Application Innovation through Cloud & Data
Transactional Apps with Azure Database for PostgreSQL
What does it mean for an application to be cloud-based? Does it mean that it was built from the ground up to run in the cloud? Do all of its components have to live there, or can parts of it still run on your own servers? The answer is... any of the above.
The customer scenario in the next section highlights a company like many internet-based companies that exist today. They are on the verge of experiencing explosive growth, and they are uncertain about whether they can deliver. No one wants to make a bad impression on users, especially new ones, who typically decide within seconds whether they want to use your services. Can you relate?
Much of the focus of this article is about making sure your database is properly set up for cloud scenarios. When you open up your application to the power of the cloud, it is very important that your database is configured in the best way possible so it does not become the limiting factor of your application. We also highlight several database features that help you unlock the full potential of your database before you need to consider a change in your application architecture or spend a lot of time adding similar capabilities in your application code.
The MyExpenses sample customer scenario
MyExpenses is an application that aims to provide a comprehensive expense tracking system for companies all over the world. Every employee can log expenses using the MyExpenses web portal and get them reimbursed in either cash or company points, which can be spent in the company store without leaving MyExpenses. Managers can do everything an employee can, but can also review, approve or reject the expense reports submitted by team members.
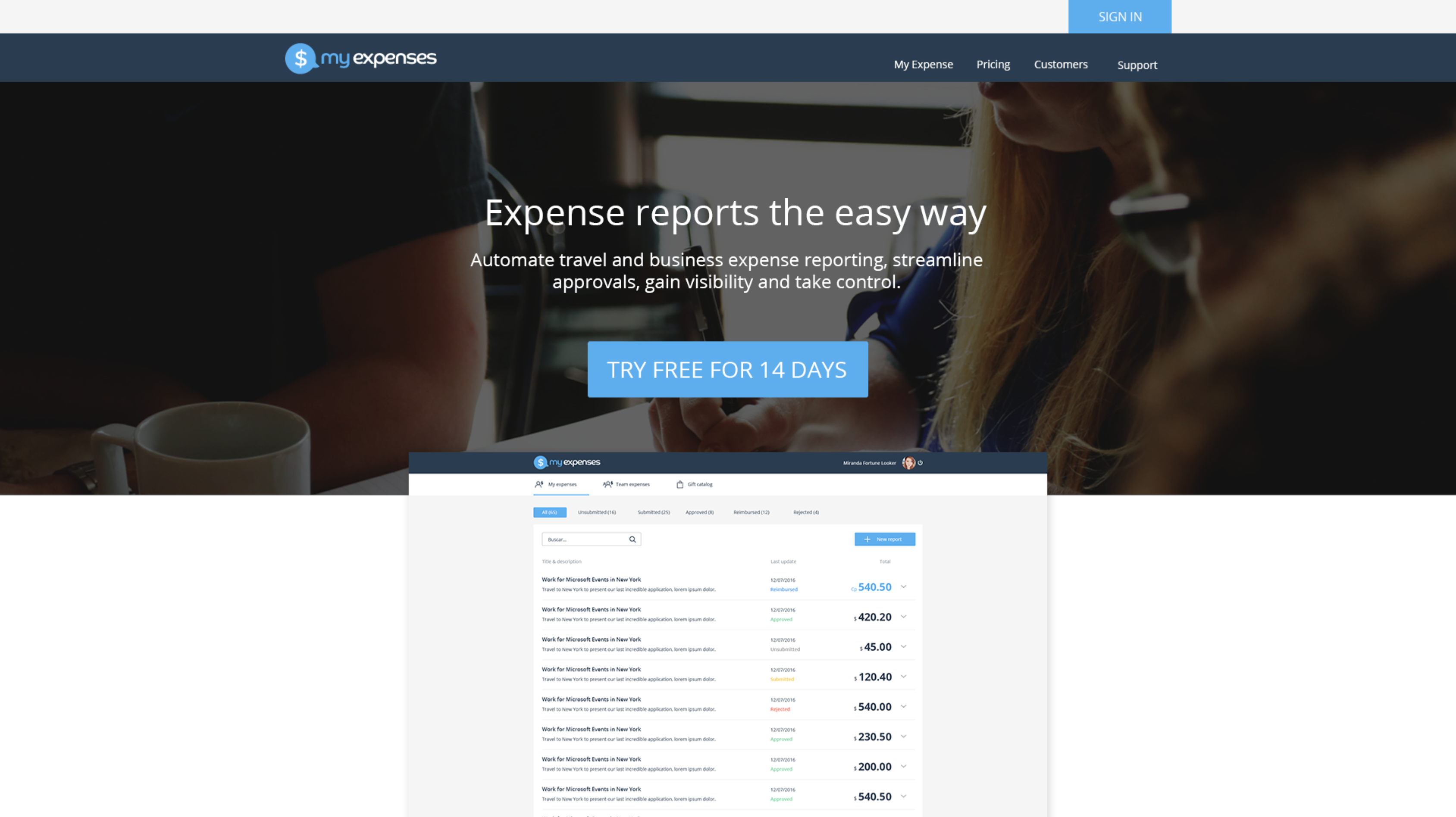
MyExpenses uses an AngularJS single-page application (SPA) for the front-end, Node.js for the back-end, and PostgreSQL as the database server.
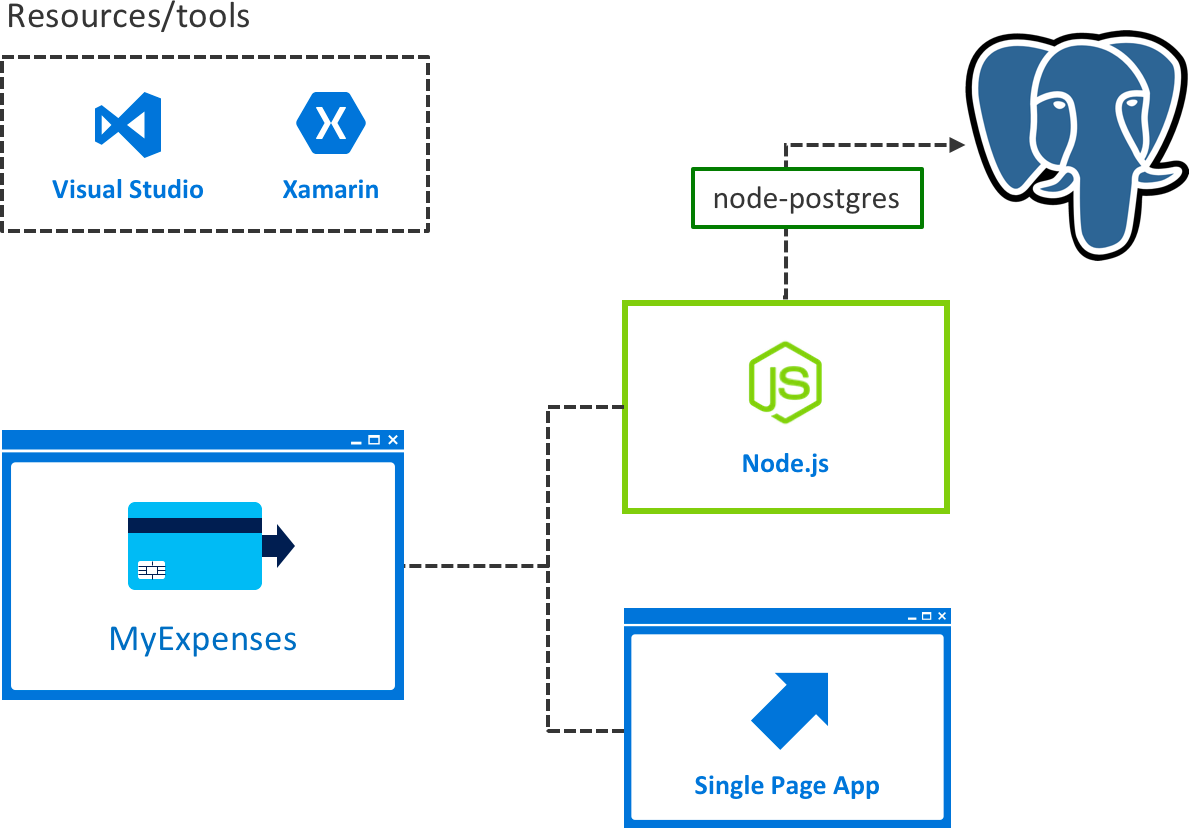
The MyExpenses development team was tasked with making improvements to the overall architecture of the application, with a focus on performance improvements, stability, and modernization. To meet these needs, the team set out to achieve the following goals:
- Move the database to the cloud
- Improve speed and resiliency
- Scale the database on demand
- Protect your data and your brand
- Manage emerging application requirements
- Sneak peak to cloud services that accelerate innovation
Move the database to the cloud
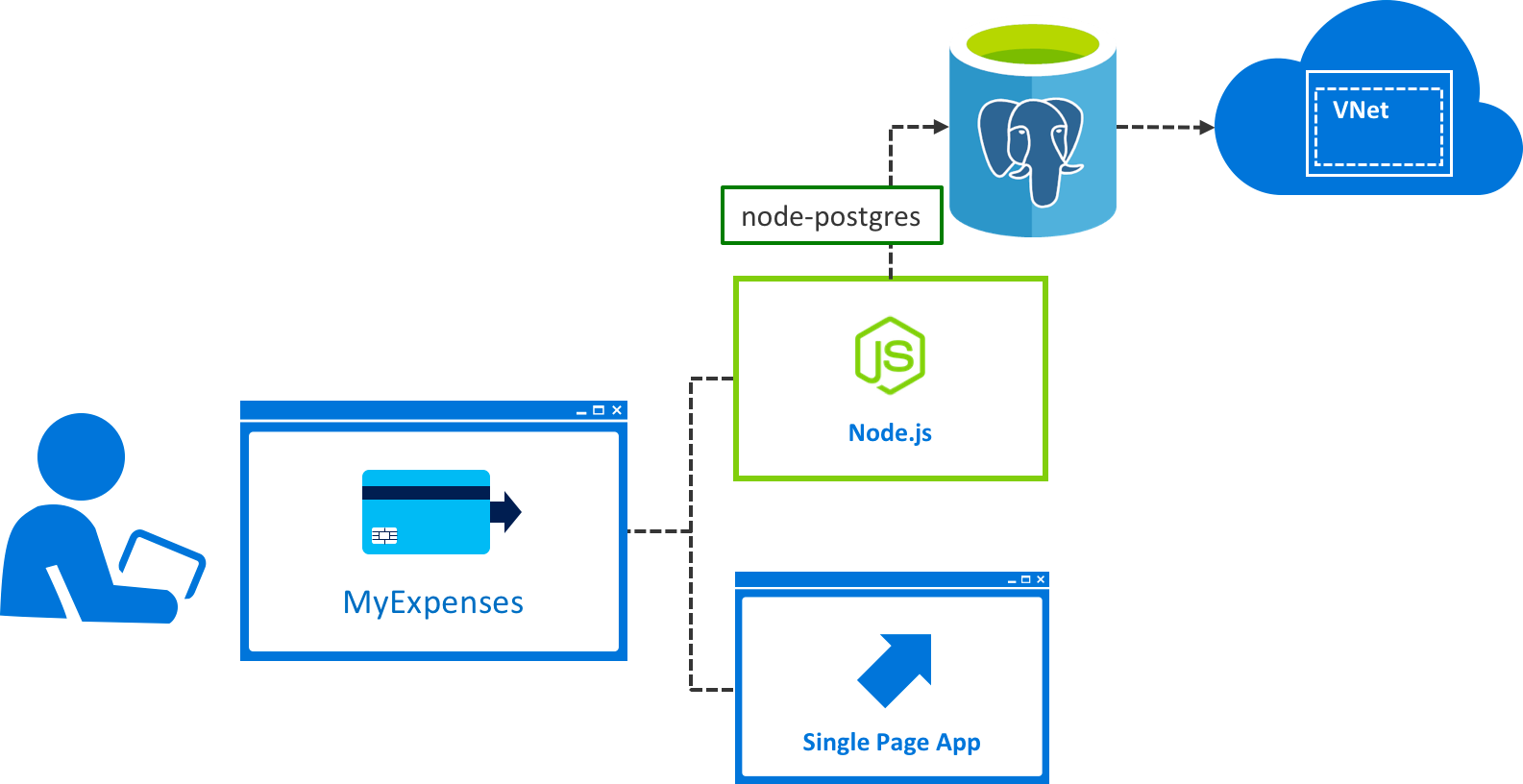
After considering lift-and-shift options for their database and application using virtual machines (VMs) in Azure, the MyExpenses development team decided they would prefer to explore options for a fully-managed, cloud-based database-as-a-service. They currently run PostgreSQL on-premises, which means they are responsible for applying patches to the operating system, as well as the database. In doing this, they experience downtime for applying patches, require their employees to work after-hours to patch or upgrade, and sometimes they are not very good at keeping up with these updates.
They are interested in using a fully-managed database service that could simplify the day-to-day management of their data platform, allowing them to spend less time managing infrastructure, and more time improving their application and core services. They are also looking to eliminate application downtime caused by patching and upgrades. However, the team has expressed some concerns with running their database and application on a public cloud platform. Namely, they have two primary concerns:
- Is it time-consuming and costly to migrate apps to the cloud?
- Does running on a public cloud pose a greater security threat versus running on-premises?
Proposed solution: Migrate PostgreSQL to Azure Database for PostgreSQL
After reviewing the options, MyExpenses decided that Azure Database for PostgreSQL provides the platform required to meet the team's desire to focus on rapid application development and accelerating their time to market, and they can make the transition without having to make code changes to their application. They will only need to update their database connection string. Azure Database for PostgreSQL is a relational database service based on the open source Postgres database engine. It provides the security, performance, high availability, and dynamic scalability the MyExpenses team is looking for, all in a fully-managed database offering, capable of handling mission-critical workloads. In addition, they can continue to develop their application with the open-source tools and platform they are familiar with, and deliver with the speed and efficiency their business demands without having to learn new skills.
To migrate an on-premises PostgreSQL database into Azure Database for PostgreSQL, there are three options:
- Dump & restore: Use
pg_dumpto extract a PostgreSQL database into a dump file, andpg_restoreto restore the PostgreSQL database from an archive file created bypg_dump. To learn more about this approach, see Migrate your PostgreSQL database using dump and restore. - Import & export: Use
pg_dumpto export a PostgreSQL database into a script file, andpsqlto import the data into the target database from that file. To learn more, see Migrate your PostgreSQL database using export and import. - Minimal-downtime migration: Migrate an existing PostgreSQL database to Azure Database for PostgreSQL by using Attunity Replicate for Microsoft Migrations. Attunity Replicate is a joint offering from Attunity and Microsoft, included at no additional cost to Microsoft customers. To learn more about this option, see Minimal-downtime migration to Azure Database for PostgreSQL.
With the MyExpenses database now migrated from on-premises to the cloud, the team only needs to modify their database connection settings in the server.config.js file in their application.
Here's what the settings are currently:
'use strict';
let config = {
port: process.env.port || 8000,
path: 'api',
serverName: 'DemoExpenses',
db: {
userName: process.env.databaseUsername || 'experience2',
password: process.env.databasePassword || 'P2ssw0rd@Dev',
database: process.env.database || 'Expenses',
options: {
host: process.env.databaseServer || 'localhost',
}
}
};
module.exports = config;
All that needs to be done is to change this configuration file to point to the Azure Database for PostgreSQL database. No other application code needs to be changed!
'use strict';
let config = {
port: process.env.port || 8000,
path: 'api',
serverName: 'DemoExpenses',
db: {
userName: process.env.databaseUsername || '{YOUR_USERNAME}',
password: process.env.databasePassword || '{YOUR_PASSWORD}',
database: process.env.database || '{YOUR_AZURE_DB_FOR_POSTGRESQL_DATABASE_NAME}',
options: {
host: process.env.databaseServer || '{YOUR_AZURE_DB_FOR_POSTGRESQL_SERVER_NAME}.postgres.database.azure.com',
port: process.env.databasePort || 5432,
ssl: true
}
}
};
module.exports = config;
Work through the hands-on example in the Developer Immersion lab.
Improve speed and resiliency
Let's turn our focus to the MyExpenses application and how it uses database features. Ever since a successful campaign to sign on new companies to their services, MyExpenses has experienced an explosion in the number users. Now, the development team wants to make sure they have the right architecture to maximize database performance, as well as resiliency required to recover from user errors.
Below is a list of their challenges, followed by proposed solutions. Some solutions contain interactive blocks of code you can use for some hands-on experience. Most offer links to labs for a more in-depth experience.
Recover from user errors saved to the database
It is important for MyExpenses to be able to track changes made to expenses by users, such as updating an expense amount and deleting data. Additionally, they want to protect themselves from the application accidentally overwriting good data with bad data due to an application defect, and other bug. Sadly, currently there is no way to do this, since each change overwrites the previous value. The MyExpenses team is evaluating adding auditing capabilities into the application, but is concerned about the development time involved, and potential performance impacts on the database, so they are interested in any capabilities of Azure Database for PostgreSQL that may be able to leverage to recover from user errors saved to the database.
Proposed solution: Recover from user errors more easily with point-in-time-restore
Until they have auditing functionality developed, the MyExpenses development team has decided to make use of the automatic backup capabilities offered by the Azure Database for PostgreSQL service. This service will allow them to recover from various disruptive events, such as a user unintentionally deleting or modifying data. To learn more about business continuity and automated backups with Azure Database for PostgreSQL, visit this link.
With point-in-time-restore, the MyExpenses team has the ability to restore their database server to a known good point in time. Using this functionality, they can retrieve user modified or deleted data and restore it to its previous state. This works by restoring the database to a new server, from which they can either replace the original server with the newly restored server or copy the needed data from the restored server into the original server.
To accomplish this, they would enter a command similar to the following at the Azure CLI command prompt:
az postgres server restore --resource-group myexpenses --server demoexpenses-restored --restore-point-in-time 2018-03-06T13:59:00Z --source-server DemoExpensesThe
az postgres server restorecommand is synchronous. After a server is restored, it can be used again to repeat the process for a different point in time, each time creating a new server.
Recover from an Azure regional data center outage
Although rare, an Azure data center can have an outage. When an outage occurs, it causes a business disruption that might only last a few minutes, but could last for hours. For MyExpenses, waiting for the server to come back online when the data center outage is over in not an option.
Proposed solution: Recover from data center outage with geo-restore
Using the Azure Database for PostgreSQL's geo-restore feature that restores the server using geo-redundant backups provides a solution for this scenario. Azure Database for PostgreSQL provides the flexibility to choose between locally redundant or geo-redundant backup storage. When the backups are stored in geo-redundant backup storage, they are not only stored within the region in which the server is hosted, but are also replicated to a paired data center. These backups are accessible even when the region your server is hosted in is offline. You can restore from these backups to any other region and bring your server back online in the event of a disaster. To learn more about the geo-restore feature, see Backup and restore in Azure Database for PostgreSQL.
Important: Geo-restore is only possible if you provisioned the server in a General Purpose or Memory Optimized tier, with geo-redundant backup storage enabled.
Geo-restore uses the same technology as point in time restore with one important difference. It restores the database from a copy of the most recent daily backup in geo-replicated blob storage (RA-GRS). For each active database, the service maintains a backup chain that includes a weekly full backup, multiple daily differential backups, and transaction logs saved every 5 minutes.
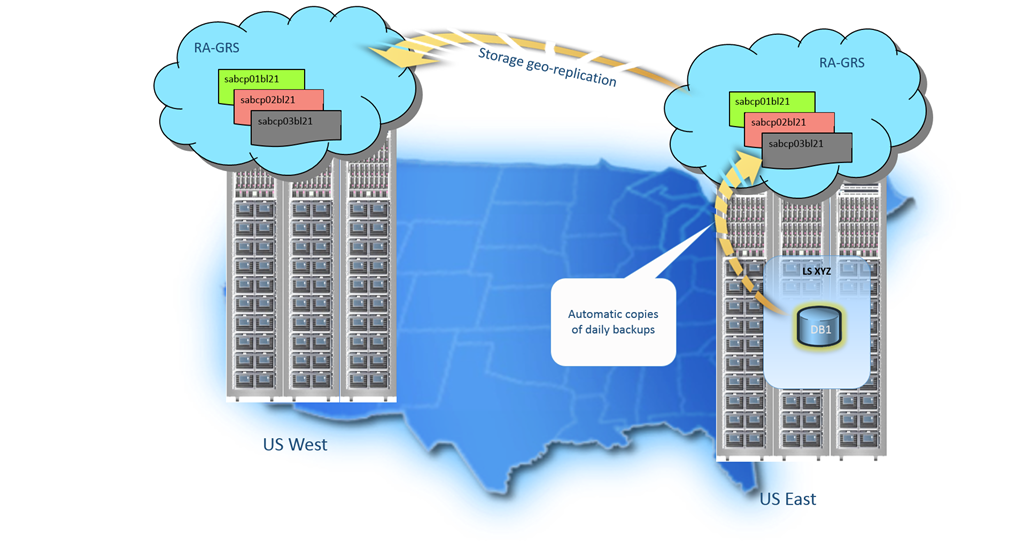
If a large scale incident in a region results in unavailability of your database application you can use geo-restore to restore a database from the most recent backup to a server in any other region.
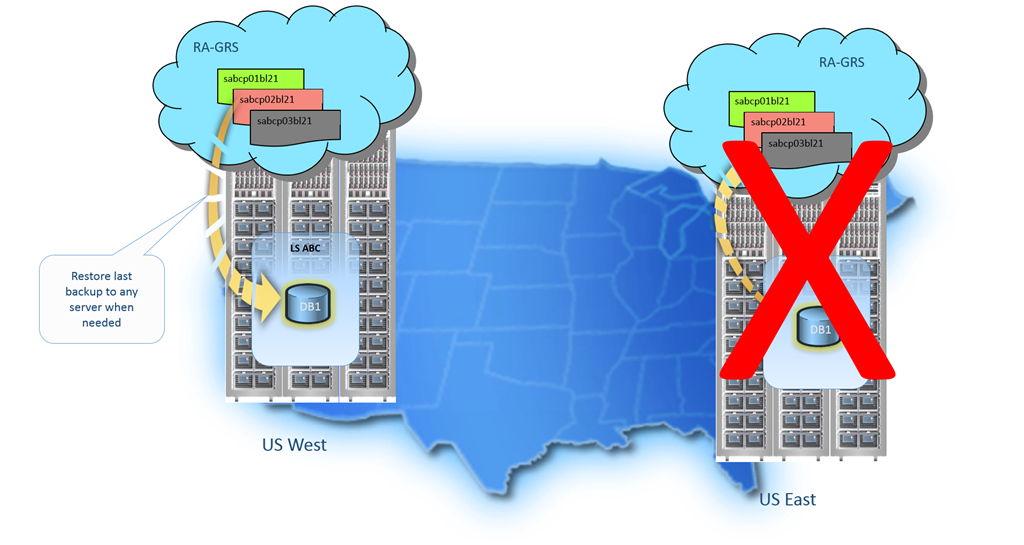
Geo-restore can be invoked from the Azure Management Portal using the Backups tab on an affected server. This tab provides a list of all the available backups for all databases on that server, showing the last backup time for each database. Once you have selected a backup for restore you can provide a name for the new database and specify the target server, which may be in any region.
Work around slow disks and bottlenecks
There are tens of thousands of MyExpenses users all over the world, and for most of them performance is a really important feature: sometimes a deal-breaker. One of the concerns expressed by the MyExpenses development team with implementing an audit table to track user activities has been the performance implications associated with having a table where each and every request and response is stored. This will result in high levels of concurrent operations generated by the web application. The more the web application is used, the more traffic will hit that table. This could be a performance problem impacting the entire database due to IO operations, and lead to degraded performance across the whole application.
Proposed solution: Accelerated transactional processing with memory-optimized tier
There are a few ways to address this problem from an application development perspective. The possibilities range from simple, such as unblocking database calls by using asynchronous functions, to complex rewrites involving decoupling your application components as much as possible using stateless microservices and relying on eventual concurrency of your data. This last example is something that Service Fabric can help you create.
However, oftentimes it is possible to make drastic improvements in performance by using new database features, avoiding any changes to the application itself. In this case, we can improve throughput to the affected tables by choosing the Memory Optimized pricing tier when creating the database in Azure. The Memory Optimized tier provides double the amount of memory per vCore compared to the General tier, and is designed for high-performance database workloads requiring in-memory performance for faster transaction processing and higher concurrency. To learn more about using the Memory Optimized tier, visit this link.
Scale the database on demand
MyExpenses uses a database-per-tenant model, which provides good tenant isolation, but also results in limited resource sharing. One of the major challenges associated with multi-tenant applications is the management of diverse tenant stores (databases) with varied demand. Knowing their application must to be able to handle the database resource requirements for tenants of varying sizes and usage levels, as well as accommodate peak usage periods across multiple time zones, the MyExpenses team is looking for a solution which will allow their current design to be flexible enough to handle the varying and less predictable workloads that they have seen from their tenant stores, while allowing them to avoid the traditional trade-offs of higher costs and lower tenant satisfaction.
Proposed solution: Quickly scale the database up or down
Elasticity is one of the foundational attributes of the cloud. After creating their Azure Database for PostgreSQL instance, the MyExpenses team can quickly scale up or down to meet customer demand by independently changing the vCores and amount of storage of their database server. vCores and the backup retention period can be scaled up or down, whereas the storage size can only be increased. Scaling of the resources can be done either through the portal or Azure CLI. An example for scaling using CLI can be found here.
The Azure Database for PostgreSQL allows you to scale compute on the fly without application downtime in one step. The following is a simple Azure CLI command that you will use to scale PostgreSQL database servers up or down.
# Add the Azure Database for PostgreSQL management extension
az extension add --name rdbms
# Scale up the server to provision more vCores within the same Tier
az postgres server update --resource-group myexpenses --name DemoExpenses --vcore 4
# Scale up the server to provision a storage size of 7GB
az postgres server update --resource-group myexpenses --name DemoExpenses --storage-size 7168Try out scaling the PostgreSQL database up or down...
Select a document to upload:
Application retry logic is essential
During the scale operation, an interruption to the database connections occurs. The client applications are disconnected, and open uncommitted transactions are canceled. It is important that PostgreSQL database applications are built to detect and retry dropped connections and failed transactions. When an Azure Database for PostgreSQL is scaled up or down, a new server instance with the specified size is created. The existing data storage is detached from the original instance, and attached to the new instance. Once the client application retries the connection, or makes a new connection, they are directed the connection to the newly sized instance.
Knowing when to scale up or down
The next challenge for the MyExpenses team is knowing when to scale up or down, based on workloads in their databases scattered throughout various regions in the world. The team was looking for a solution which could alert them about resource utilization, and help them to decide when to dial up or down?
Proposed solution: Azure monitoring and alerting
Using the built-in Azure monitoring and alerting features, you can quickly assess the impact of scaling up or down based on your current or projected performance or storage needs. Alert triggers can be created when the value of a specified metric crosses a threshold you assign. The alert triggers both when the condition is first met, and then afterwards when that condition is no longer being met. See Alerts for details.
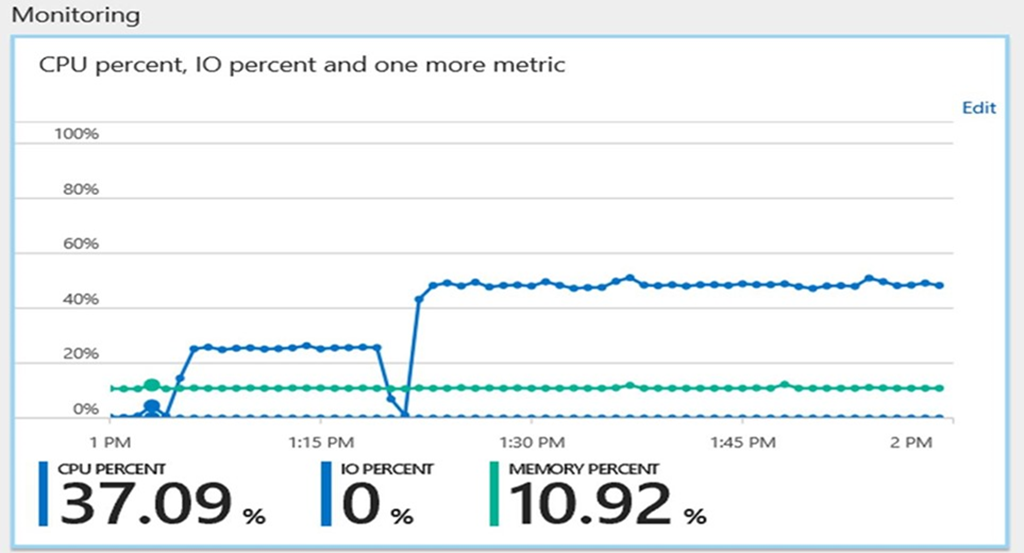
To query your Azure Database for PostgreSQL databases CPU and storage utilization, use the following CLI command:
# Monitor usage metrics - CPU
az monitor metrics list \
--resource-id "/subscriptions/00000000-0000-0000-0000-000000000000/resourceGroups/myexpenses/providers/Microsoft.DBforPostgreSQL/servers/demoexpenses" \
--metric-names cpu_percent \
--time-grain PT1M
# Monitor usage metrics - Storage
az monitor metrics list \
--resource-id "/subscriptions/00000000-0000-0000-0000-000000000000/resourceGroups/myexpenses/providers/Microsoft.DBforPostgreSQL/servers/demoexpenses" \
--metric-names storage_used \
--time-grain PT1MPT1M is the granularity of the available measurement (1-minute intervals). Using different granularities gives you different metric options.
Scale app with spikes in demand
Up to this point, our focus has been on the database, and how to move that to the cloud, without having to make application code changes. Let's now shift focus to application changes which can help MyExpenses meet demand for their application. There are certain periods in which MyExpenses experiences heavy spikes in demand. These spikes cannot always anticipated, and it is difficult for them to handle the load when it happens. Using monitoring and alerts, they now have the ability to quickly scale their database when alerted, but they don't currently have the same capabilities with their on-premises application servers. Also, they would like to make frequent updates to evolve their app, and they are interested in learning more about ways to stage their updates, and to scale elastically to handle spikes in demand.
Proposed solution: Move the application to a managed App Service
After learning that Azure Database for PostgreSQL is tightly integrated with Azure Web Apps, the MyExpenses team has decided to move their application to a managed App Service in Azure. Azure App Service enables an integrated experience to deploy an Azure Web App with managed PostgreSQL making app development simple and easy! Hosting the web applications within Azure App Service will allow them to leverage the cloud for continuous app updates. App Services use what are called deployment slots, which are live apps with their own hostnames. This means that swapping between development, staging, and production deployment slots can be accomplished with no downtime (hot swap). This can greatly reduce deployment times, and provide assurances that their app is properly functioning on the cloud before committing to a deployment.
In addition, they will also gain the benefit of easily scaling their app to handle spikes in demand. Scaling up can be done by adding more CPU, memory, disk space, etc., and scale out can be handled by increasing the number of VM instances that run an app. The scale settings only take seconds to apply, and doesn't require any code changes or app redeployments.
Follow this link to learn more about scaling apps in Azure.
Protect your data and your brand
While interviewing the MyExpenses leadership, as well as developers, a common set of concerns around security of user data and the database itself, was revealed.
The app contains massive amounts of sensitive data to secure.
As developers, we often find that security considerations are pushed until late in the development process due to upfront pressure to create a working product as quickly as possible, and a tendency to focus more on the technology used, the application architecture, how domain knowledge is expressed in code and to the user, and even ways to validate the data input from the user. Other pressures, such as tight deadlines and the rhythm of business, also compound the problem.
The MyExpenses development team has put some security measures in place, but they would like to improve on what they've done. Here are some of their challenges:
Back-end filters to control access to data
Right now, the MyExpenses website controls user access to the data via JavaScript filters. Think for a moment what would happen if developers accidentally forget or delete the lines of code in charge of filtering reports. Every employee of the company would see data they are not supposed to, and this could be a big problem!
Proposed solution: Controlled access via firewall rules
Azure Database for PostgreSQL Server firewall prevents all access to the database server until you specify which computers have permission. The firewall grants access to the server based on the originating IP address of each request. To configure their firewall, the MyExpenses team created firewall rules that specify ranges of acceptable IP addresses. Firewall rules are created at the server level. To learn more, see Firewall rules
All database access to your Azure Database for PostgreSQL server is blocked by the firewall by default. To begin using your server from another computer, you need to specify one or more server-level firewall rules to enable access to your server. Use the firewall rules to specify which IP address ranges from the Internet to allow. Access to the Azure portal website itself is not impacted by the firewall rules. Connection attempts from the Internet and Azure must first pass through the firewall before they can reach your PostgreSQL Database, as shown in the following diagram:
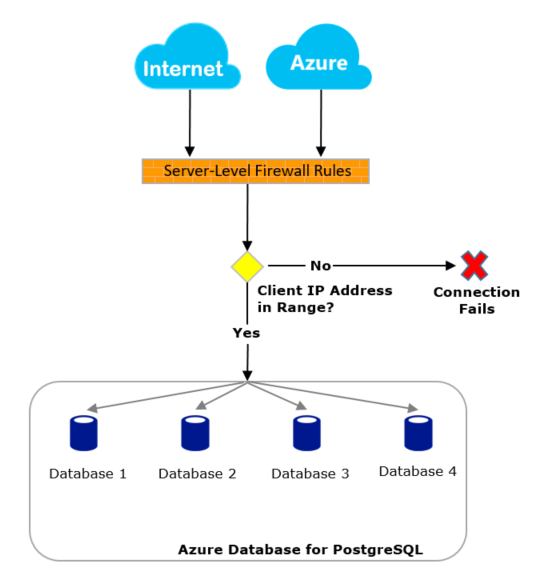
Firewall rules for Azure Database for PostgreSQL can be managed via the Azure portal or by using the Azure CLI.
To list firewall rules, run the az postgres server firewall-rule list command:
az postgres server firewall-rule list --resource-group myexpenses --server-name DemoExpensesTo create a new firewall rule, run the az postgres server firewall-rule create command.
By specifying 0.0.0.0 as the --start-ip-address and 255.255.255.255 as the --end-ip-address range, the following example allows all IP addresses to access the server demoexpenses.postgres.database.azure.com
az postgres server firewall-rule create --resource-group myexpenses --server-name DemoExpenses --name AllowIpRange --start-ip-address 0.0.0.0 --end-ip-address 255.255.255.255Encryption protects data from a security breach
Their database contains personally identifiable information (PII) about their employees, such as social security numbers. Right now, this information is stored as plain text. The PII data is required by the human resources (HR) application for things like managing payroll and benefits for employees.
However, it's a massive risk to have such sensitive information easily accessible. The MyExpenses developers need to make sure that this information is kept secure, not only because of security audits, but because of the risk to their employees and customers if the information is accessed by a malicious attacker. They would feel better knowing that the data is encrypted at rest in the file system, and is not vulnerable to someone running exhaustive ad-hoc queries. They also need to know the data is protected in the event of a security breach where a malicious attacker has access to the files.
Proposed solution: Encryption for data at-rest
Azure database services have a tradition of data security that Azure Database for PostgreSQL upholds with features that limit access, protect data at-rest and in-motion, and help you monitor activity. Visit the Azure Trust Center for information about Azure's platform security.
The Azure Database for PostgreSQL service uses storage encryption for data at-rest. Data, including backups, is encrypted on disk (with the exception of temporary files created by the engine while running queries). The service uses AES 256-bit cipher that is included in Azure storage encryption, and the keys are system managed. Storage encryption is always on and cannot be disabled.
By default, the Azure Database for PostgreSQL service is configured to require SSL connection security for data in-motion across the network. Enforcing SSL connections between the database server and client applications helps protect against "man in the middle" attacks by encrypting the data stream between the server and applications. Optionally, requiring SSL can be disabled for connecting to your database service if your client application does not support SSL connectivity.
Manage identity across multiple log-in systems
Another issue the MyExpenses team is looking to address is the management of user accounts. Historically, the team has created individual user accounts for each application throughout the organization, and users have had to remember passwords for each. This process has been time-consuming and difficult to organize, and only allows for limited integration with diverse platforms and devices.
Proposed solution: Streamlined access management with Azure Active Directory
Using Azure Active Directory (AAD) provides a simple and efficient means of managing user accounts through single sign-on. Single sign-on means being able to access all of the applications and resources that you need to do business, by signing in only once using a single user account. Once signed in, you can access all of the applications you need without being required to authenticate (e.g. type a password) a second time. Azure AD enables easy integration to many of today’s popular SaaS applications; it provides identity and access management, and enables users to single sign-on to applications directly, or discover and launch them from a portal such as Office 365 or the Azure AD access panel. AAD also provides self-service for users, and is compatible with multiple platforms and devices. For more information on using Azure AD, see Authenticate user Azure AD and OpenID Connect

Manage emerging application requirements
Since MyExpenses has been deployed, there have been several emerging requirements to add new features and address issues. This is typical while maintaining custom-built applications, but the development team has brought up a few pain points that make it difficult to keep up with demand.
Addressing Business Intelligence (BI) needs
One of MyExpenses' challenges is not having a centralized location to view reports across all businesses using the app, or narrowed down to a single business entity. To address the issues of fixed data storage and weak BI constraining data-driven decisions.
Proposed solution: Azure SQL DW and Power BI
The MyExpenses team is implementing Azure SQL Data Warehouse (SQL DW). Azure SQL Data Warehouse connected to a service such as Power BI, will provide good insight into total expenses per month, highest number of expenses by category, and other useful data.
Azure SQL Data Warehouse is a cloud-based, scale-out database capable of processing massive volumes of data, both relational and non-relational. Built on Microsoft's massively parallel processing (MPP) architecture, Azure SQL Data Warehouse can handle your enterprise workload.
- Combines the SQL Server relational database with Azure cloud scale-out capabilities. You can increase, decrease, pause, or resume compute in seconds. You save costs by scaling out CPU when you need it, and cutting back usage during non-peak times.
- Leverages the Azure platform. It's easy to deploy, seamlessly maintained, and fully fault tolerant because of automatic back-ups.
- Complements the SQL Server ecosystem. You can develop with familiar SQL Server Transact-SQL (T-SQL) and tools.
Azure SQL Data Warehouse uses the Microsoft massively parallel processing (MPP) architecture, designed to run some of the world's largest on-premises data warehouses. By combining MPP architecture and Azure storage capabilities, Azure SQL Data Warehouse can:
- Grow or shrink storage independent of compute.
- Grow or shrink compute without moving data.
- Pause compute capacity while keeping data intact.
- Resume compute capacity at a moment's notice.
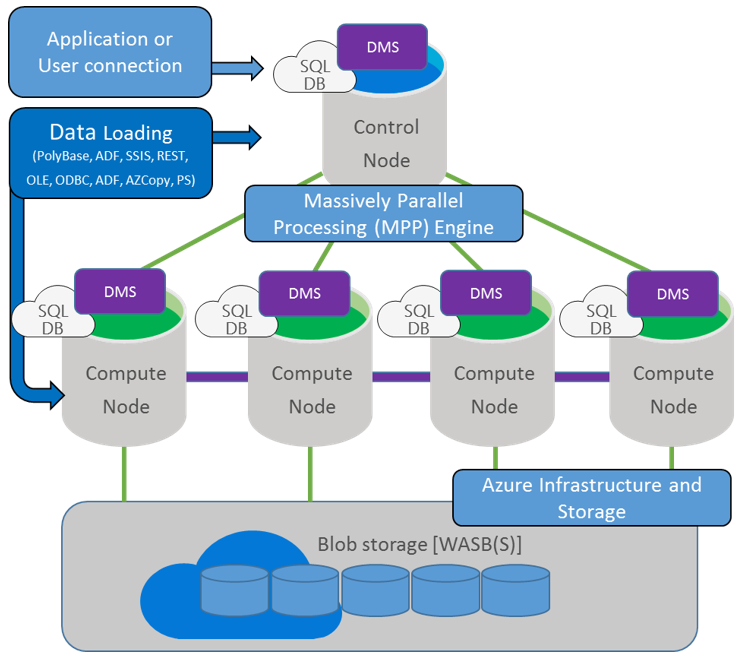
Power BI Embedded is an Azure service that enables ISVs and app developers to surface Power BI data experiences within their applications. As a developer, you've built applications, and those applications have their own users and distinct set of features. Those apps may also happen to have some built-in data elements like charts and reports that can now be powered by Microsoft Power BI Embedded. Users don’t need a Power BI account to use your app. They can continue to sign in to your application just like before, and view and interact with the Power BI reporting experience without requiring any additional licensing.
Try the Power BI Embedded exercises for yourself in the Developer Immersion lab.
Sneak peak to cloud services that accelerate innovation
In the previous scenario, we migrated the on-premises PostgreSQL database to Azure DB for PostgreSQL, so it is now fully cloud-based. This gives the MyExpenses team a chance to move their transactional application to the cloud, and modernize it by adding intelligence capabilities offered by various Azure services, such as Azure App Services, Azure Search, and Azure Machine Learning, which are better suited for a database on the cloud.
They have asked for guidance on which services they should use, and ideas for improvements that can be made quickly without too many changes to their application.
Idea! Make expenses and gift catalog searchable
MyExpenses users are telling the customer support team that, as they add more and more expenses, it's getting more difficult for them to find specific expenses using the provided filters. For instance, they might not have the expense Id at hand or know the associated account number, but they do know the name of the item or location, or other details that are not currently available through the filters offered.
They also would like to easily search the gift catalog for specific items by name or description. Creating a search interface, as well as creating or integrating a search engine into the MyExpenses application will take more time than they'd like. Plus, the MyExpenses developers aren't exactly search experts.
Proposed solution: Add search capabilities using Azure Search
Azure Search is a cloud search-as-a-service solution that delegates server and infrastructure management to Microsoft, leaving you with a ready-to-use service that you can populate with your data and then use to add search functionality to your web or mobile application. Azure Search allows you to easily add a robust search experience to your applications using a simple REST API or .NET SDK without managing search infrastructure or becoming an expert in search.
Check the following link for more information about Azure Search.
The steps to get going are quite simple:
- Create a new Azure Search service in your Azure subscription.
- Use the Azure Search interface to import data from your Azure Database for PostgreSQL.
- Create new search indexes: one for Products, and one for Expenses (Azure Search automatically recommends indexes for you to quickly get started).
- Create an indexer, which is a scheduler that makes sure your indexes are up-to-date.
From here, you have everything you need set up for search! You can use your Azure Search instance's search explorer to test queries and see what the results look like. All results are returned in JSON format so you can easily process them from within your app. A few modifications will need to be made within the MyExpenses app to call the Azure Search REST API to conduct searches against the indexes.
The code below consists of two methods in the MyExpenses Node.js web application which implement the search logic. The first method, getProducts accepts a search filter, results paging parameters, and a base Url for viewing product information. It used to execute searches against the database directly, but the azureSearchRequest method was added to call the Azure Search service API, accepting a requestPath parameter that passes the extended path and querystring parameters to the Search API http endpoint. As you can see, getProducts calls azureSearchRequest first with the $countquery parameter to get the total number of products in the products index, followed by another call containing the $top, $search, and the optional $skip query parameters to retrieve the number of records, with the given filter, skipping the specified number of records, respectively.
To use this code, be sure to replace
{YOUR_AZURE_SEARCH_NAME}and{YOUR_AZURE_SEARCH_KEY}with your Search API values.
let getProducts = function (filter, pageIndex, pageSize, baseUrl) {
let offset = pageIndex * pageSize;
// Search filter. '*' means to search everything in the index.
let search = filter ? filter : '*';
// Path that will be built depending on the arguments passed.
let searchPath = '/indexes/products/docs?api-version=2015-02-28&$top=' + pageSize + '&search=' + search;
// Request needed to get the total number of documents available, so pagination works as expected.
let totalCountPath= '/indexes/products/docs/$count?api-version=2015-02-28';
if (offset > 0) {
searchPath += '&$skip=' + offset;
}
return azureSearchRequest(totalCountPath).then(count => {
return azureSearchRequest(searchPath).then(responseString => {
var responseObject = JSON.parse(responseString);
// We map the values not to alter the buildProducts function.
var mappedResponse = responseObject.value.map((val) => ({
id: val.Id,
title: val.Title,
price: val.Price,
description: val.Description
}));
return buildProducts(mappedResponse, pageIndex, pageSize, baseUrl, parseInt(count, 10));
});
});
};
let azureSearchRequest = function (requestPath) {
var options = {
hostname: '{YOUR_AZURE_SEARCH_NAME}.search.windows.net',
method: 'GET',
path: requestPath,
headers: {
'api-key': '{YOUR_AZURE_SEARCH_KEY}',
'Content-Type': 'application/json'
}
};
// Request to get the number of elements.
let deferred = new Promise((resolve, reject) => {
var req = https.request(options, function (res) {
res.setEncoding('utf-8');
var responseString = '';
res.on('data', function (data) {
responseString += data;
});
res.on('end', function () {
console.log(responseString);
resolve(responseString);
});
});
req.on('error', function (e) {
reject(e);
console.error(e);
});
req.end();
});
return deferred;
}
Learn more about configuring and using the Azure Search API with this Developer Immersion lab.
Next Steps
Activate your own free Azure account
- Set up Azure environment & build sample application
- GitHub Developer Immersion Lab
- Access Azure Database for PostgreSQL code samples in GitHub Reference Implementation Repository