Big Data and Analytics
Incorporate intelligence into your applications
Incorporating intelligence into your application, while processing big data and and employing advanced analytics, is unfamiliar territory for many. This interactive scenario walks you through common challenges in this space, and allows you to try some of the concepts for yourself—all without any setup or configuration on your part.

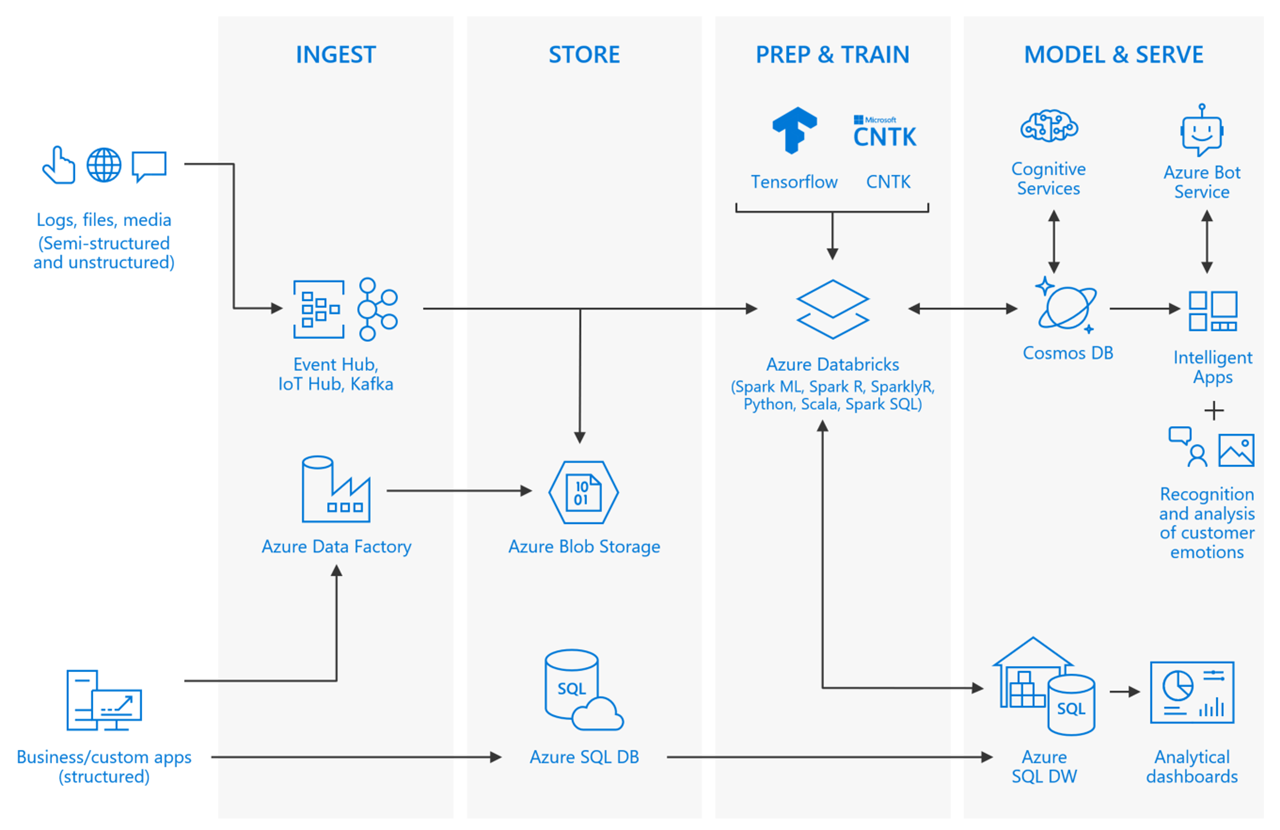
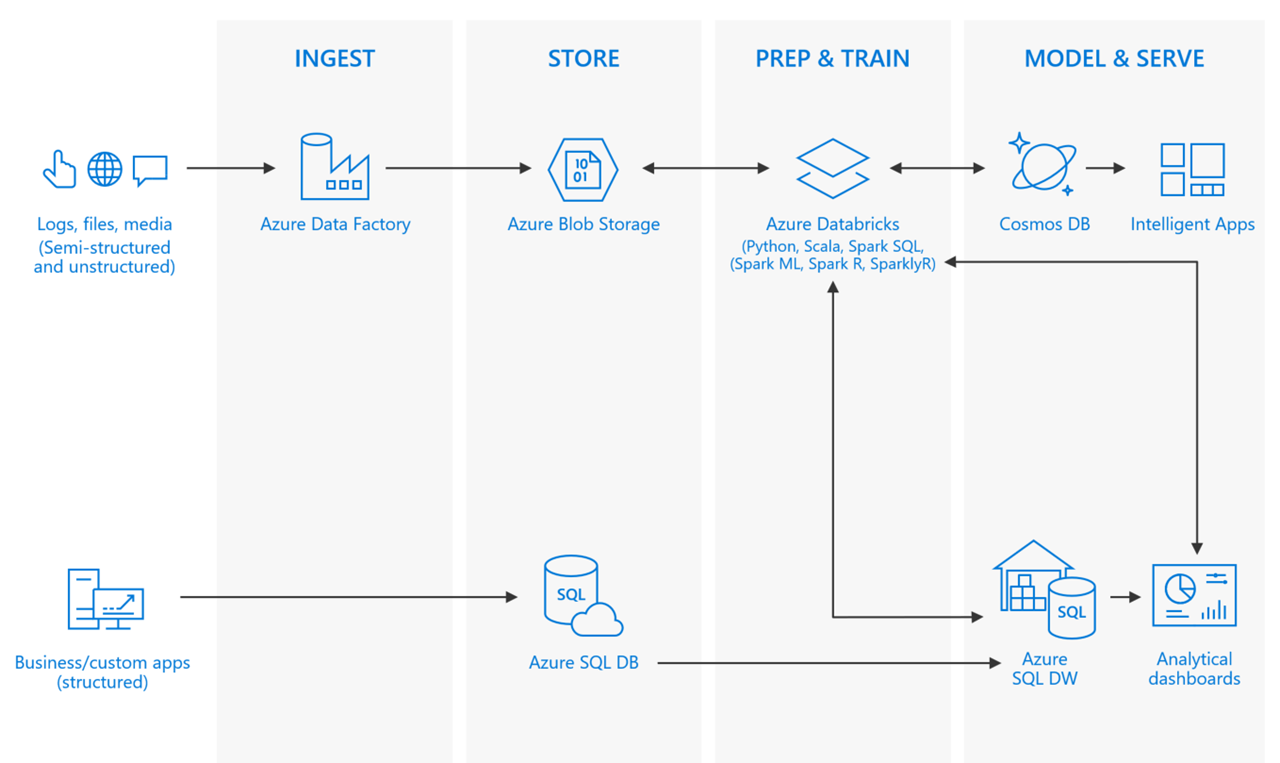
Developing software today is not like it was 20 years ago. In many respects, it's much different than developing 5 years ago, from a high vantage point. Besides the tools used to develop software, the platforms on which your software runs, and the myriad libraries that are available today, what has changed? For many, the data landscape has changed. What you can do, are expected to do, with that data has changed. The cost of storage keeps plummeting, while the means by which data is collected keeps growing. The old data doesn't just go away, in many respects. Some data arrives at a rapid pace, constantly demanding to be collected and observed. Others come in slow, but very large chunks, oftentimes in the form of decades of historical data. You might be facing an advanced analytics problem, or one that requires machine learning. The trouble is, the world of software development and those of big data and advanced analytics seem like they are light years apart. There are lots of choices to solve very different problems. They use different software stacks, different engineering approaches, and different terminology. Where do you begin?
Let's back up a little and define big data. It's a term used for data sets that are so large or complex that traditional data processing application software is inadequate to deal with them. Big data has its own set of challenges, such as capturing data, data storage, data analysis, search, sharing, transfer, visualization, querying, updating, and information privacy.
To help frame these challenges in a way you can relate to, we will follow the story of the fictitious Wide World Importers, and how they can address their big data and analytics needs.
The Wide World Importers sample customer scenario
Wide World Importers (WWI) is a traditional brick and mortar business with a long track record of success, generating profits through strong retail store sales of their unique offering of affordable products from around the world. They have a great training program for new employees, that focuses on connecting with their customers and providing great face-to-face customer service. This strong focus on customer relationships has helped set WWI apart from their competitors. Now they want to expand their reach to customers around the world through web and mobile e-commerce. But they don't want to just simply make their inventory available online. They want to build upon their track record of strong customer connections, and engage with their customers through personalized, high-quality application experiences that incorporate data and intelligence.

This is their omni-channel strategy:

WWI has recognized that moving to an omni-channel strategy has quickly outgrown their ability to handle data. They anticipate the following solutions needed to reach more customers and grow the business:
- Scale with ease to reach more consumers
- Unlock business insights from unstructured data
- Apply real-time analytics for instant updates
- Infuse AI into apps to actively engage with customers
To address these challenges head-on, the WWI development team set out to achieve the following goals
- Working with a modern data warehouse
- Unlock business insights from unstructured data
- Analyze Big Data to uncover insights
- Now with all this data, advanced analytics come into play
- Enabling real-time processing
- Artificial Intelligence
Working with a modern data warehouse
Wide World Importers' (WWI) new omni-channel strategy dramatically increases volume and sources of customer data. This increased demand can overwhelm existing resources, lead to inefficient data storage investments, and hinder insights. They need an easy way to scale, that will address these concerns, and allow them to share insights across all information sources through one single version of truth.
Below is a list of their challenges, followed by proposed solutions. Some solutions contain interactive blocks of code you can use for some hands-on experience. Most offer links to labs for a more in-depth experience.
We need help bringing all data sources into a single data warehouse
Prior to expanding to our current omni-channel strategy, we had a simple Point of Sale (POS) application that handled customer orders at each retail store. The back-end was a series of service layers used to process orders and store them in a SQL database. We were equipped to handle this level of data.
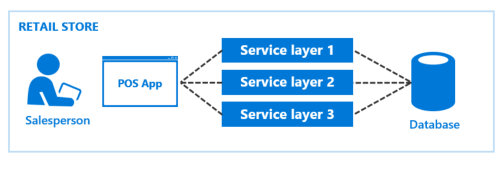
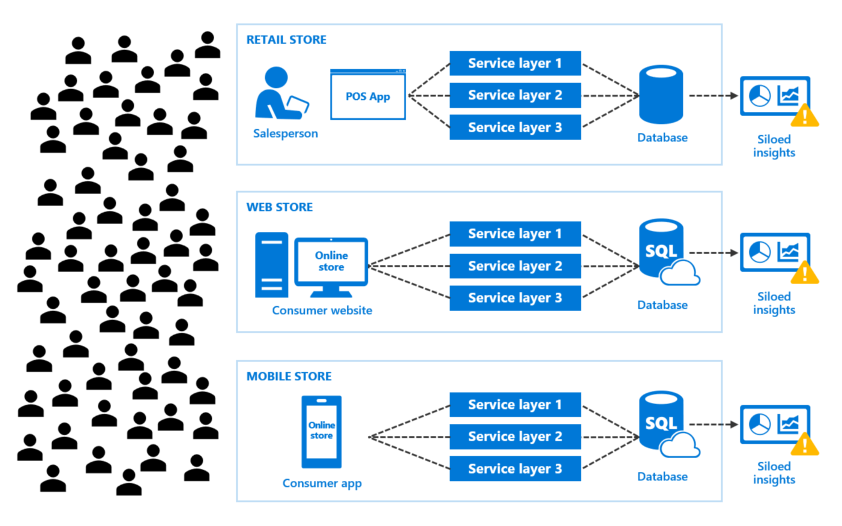
As we added new e-commerce channels to expand the customer base, consumer demand also increased. This increased demand from more customers ordering products through more channels generated more data. Now we have new problems we need to address:
- Increased consumer demand, leading to increased app data
- We are unable to determine business trends because of siloed insights
- We have a rising data management footprint, increasing cost and complexity
- New development challenges resulting from more deployment targets and duplicated code
Proposed solution: Bring data sources together with Azure SQL Data Warehouse
Azure SQL Data Warehouse is an elastic data warehouse as a service with enterprise-class features. This elasticity allows you to grow, shrink, and pause the data warehouse in seconds, saving you money when your demand is low, while being able to scale up to handle petabytes of data with massive parallel processing when needed. The best part is, you can independently scale compute and storage within seconds. This can also save money, since data demands and compute needs don't usually increase at the same time, or at the same rate. As an added bonus, Azure SQL Data Warehouse (SQL DW) offers seamless compatibility with Power BI for visualization and dashboards, Azure Machine Learning, Azure Databricks for big data and analytics, and Azure Data Factory for automatically moving large amounts of data.
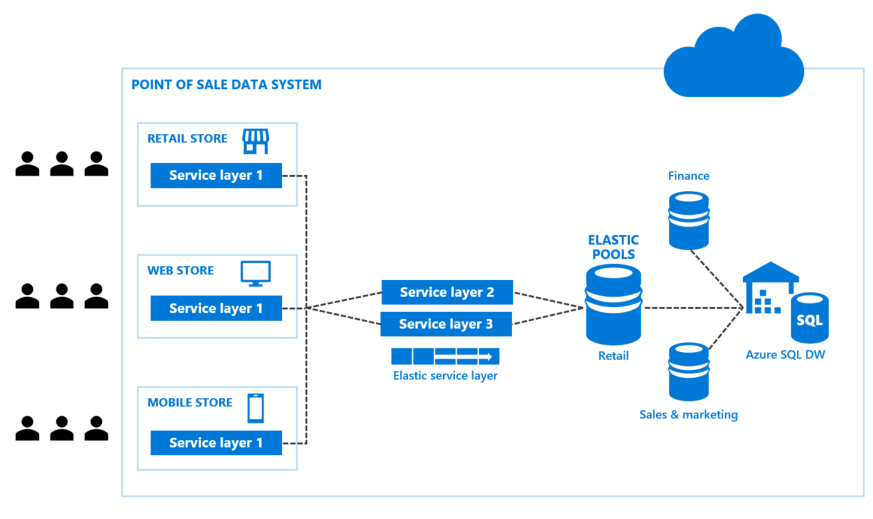
Data is stored in Azure storage, which keeps user data safe, and allows you to pay separately for SQL DW's storage consumption from its compute. In this scenario, choose Azure Data Lake storage instead of blob storage, because it is optimized for IO and has unlimited data capacity.
SQL DW's massively parallel processing (MPP) architecture allows for distribution of computational processing of data across multiple nodes. Its ability to elastically scale computation tasks also helps reduce cost. To simplify working across the compute nodes, the applications within each channel of the POS system communicate with the control node, which optimizes your queries for parallel processing and handles distributing the work across the nodes.
Check the following link for more information about Azure SQL Data Warehouse.
We would like to scale our SQL databases to meet demand, without complicating how we manage them
We have several databases we use for retail, sales and marketing, and finance data. Depending on product promotions, financial audits, marketing campaigns, and other factors, transactional load to these databases vary. We would like to be able to scale our databases, based on unpredictable usage demands. At the same time, we're concerned about needing to manage multiple (and varying) databases to perform administrative tasks, like schema changes, credentials management, performance data collection, and telemetry collection.
Proposed solution: Use SQL Database elastic pools and elastic jobs
SQL Database elastic pools can help you meet this challenge in a simple, yet cost-effective way. The databases in an elastic pool are on a single Azure SQL Database server and share a set number of resources (elastic Database Transaction Units (eDTUs)) at a set price. Within the pool, individual databases are given the flexibility to auto-scale within predefined parameters. Databases under heavy load will consume more eDTUs to meet demand, while databases under light load will consume less, or none at all.
When you start using elastic pools, you need to address how you're going to connect to the varying number of databases to run Transact-SQL (T-SQL) statements or perform other administrative tasks. This is where elastic jobs can help. An elastic job handles the task of logging in to each database in a target group. You can also define, maintain, and persist T-SQL scripts to be executed across a group of Azure SQL Databases. These can be either ad-hoc or scheduled jobs.
Elastic Database jobs is a customer-hosted Azure Cloud Service, consisting of the deployed cloud service with a minimum of two worker roles for high availability, an Azure SQL Database that acts as the control database to store all of the job metadata, an Azure Service Bus to coordinate the work, and Azure Storage to store diagnostic output logging. These components are installed and configured automatically during setup.
Learn more about elastic pools and elastic jobs.
We would like to share insights across information sources through one single version of truth
Given the current design of our omni-channel strategy, our insights are siloed. This is because data for our retail store, web store, and mobile stores are separately collected, managed, and reported on. This makes it very difficult to determine business trends, impacting our ability to pivot based on this crucial information.
Proposed solution: Use Power BI with SQL Data Warehouse and Azure Analysis Services
When you use SQL Data Warehouse, you are doing so to consolidate your data and analyze it in one place, simplifying data management and analysis. Power BI is Microsoft's premier business intelligence platform that makes it very simple to create powerful visualizations and analyze your data, then share that information through reports and static or live dashboards. While it is possible to directly connect SQL Data Warehouse directly to Power BI, you must be careful about SQL Data Warehouse's concurrency limits, depending on the selected service level. A recommended approach is to use Azure Analysis Services, which is built on the proven analytics engine in Microsoft SQL Server Analysis Services. With Azure Analysis Services, you can host semantic data models in the cloud. In this case, users within the World Wide Importers organization can then connect to the semantic data models using tools like Excel, Power BI, and many others to create reports and perform ad-hoc data analysis. Power BI can directly connect to the Azure Analysis Services instance so users can easily take advantage of the powerful visualizations that Power BI offers.
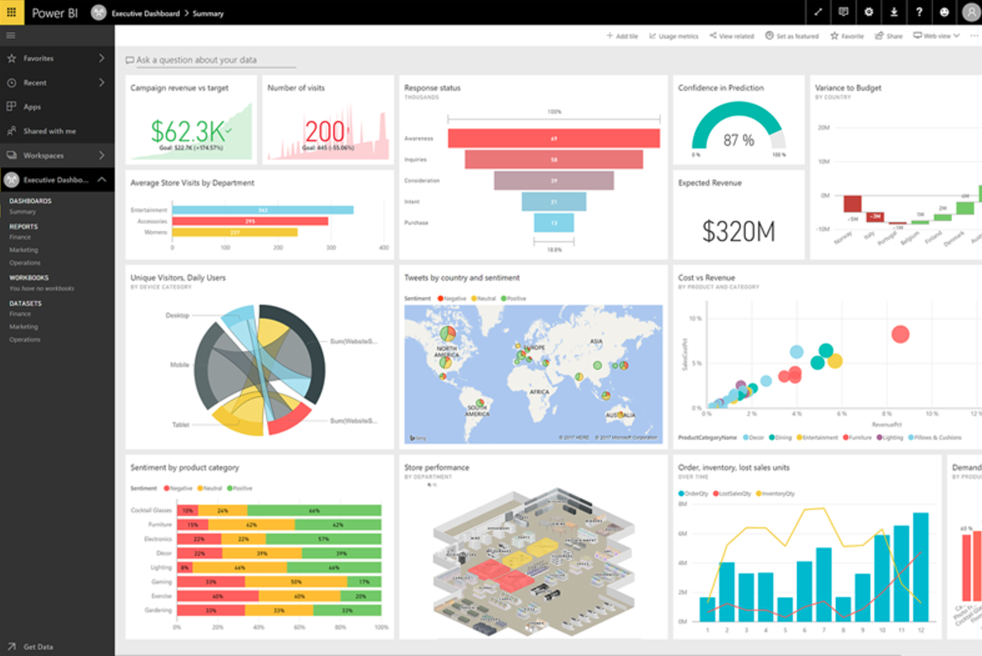
Learn more about Power BI and how to use Power BI with SQL Data Warehouse.
Unlock business insights from unstructured data
By modernizing their data platform, businesses can take advantage of ever-increasing amounts and types of unstructured data. Unstructured data means any type of data that does not have a pre-defined schema you can use to explore and analyze that data. Usually unstructured data comes in the form of a large set of flat text files, such as logs, data dumps, or social media. Wide World Importers would like to ingest and manage unstructured data from these diverse sources.
We would like to process the unstructured data and store it in our data warehouse
A lot of our data comes from diverse sources, apart from the relational data we're used to from sales transactions. For instance, we have a lot of log files being generated from all of these new services we're adding, making it harder to access and analyze all of them. Plus, we've started communicating with our customers via online chat. We store these chat sessions in a series of text files each day, and would like to be able to search those conversations and eventually analyze them to get an overall sense of customer sentiment. As you can guess, these files are all over the place, so we need an easy way to collect, parse, and analyze them all.
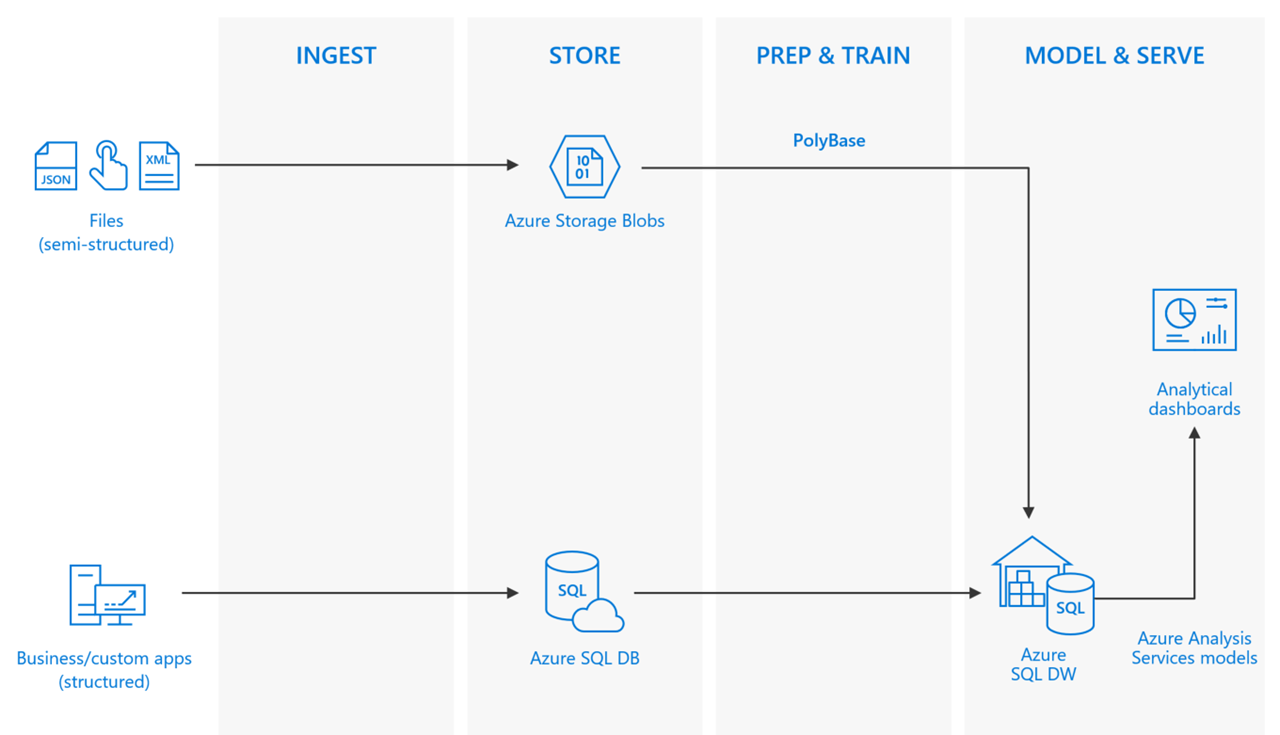
Proposed solution: Load data with PolyBase in SQL Data Warehouse
Prior to processing unstructured data, we need a place to store it. Azure Storage makes it easy to cost-effectively store terabytes of files, or blobs.
Once you have the files in Azure Storage, you need a way to access and analyze it. This is where PolyBase comes in. PolyBase is a technology that accesses data outside of the database via the T-SQL language. You can use it to run queries on external data in Azure Blob Storage, as well as import data from Azure Blob Storage or Azure Data Lake Store into SQL Data Warehouse.
PolyBase uses external tables to access data in Azure storage. Since the data is not stored within SQL Data Warehouse, PolyBase handles authentication to the external data by using a database-scoped credential.
The following example uses these Transact-SQL statements to create an external table.
- Create Master Key (Transact-SQL) to encrypt the secret of your database scoped credential.
- Create Database Scoped Credential (Transact-SQL) to specify authentication information for your Azure storage account.
- Create External Data Source (Transact-SQL) to specify the location of your Azure blob storage.
- Create External File Format (Transact-SQL) to specify the format of your data.
- Create External Table (Transact-SQL) to specify the table definition and location of the data.
-- A: Create a master key.
-- Only necessary if one does not already exist.
-- Required to encrypt the credential secret in the next step.
CREATE MASTER KEY;
-- B: Create a database scoped credential
-- IDENTITY: Provide any string, it is not used for authentication to Azure storage.
-- SECRET: Provide your Azure storage account key.
CREATE DATABASE SCOPED CREDENTIAL AzureStorageCredential
WITH
IDENTITY = 'user',
SECRET = '<azure_storage_account_key>';
-- C: Create an external data source
-- TYPE: HADOOP - PolyBase uses Hadoop APIs to access data in Azure blob storage.
-- LOCATION: Provide Azure storage account name and blob container name.
-- CREDENTIAL: Provide the credential created in the previous step.
CREATE EXTERNAL DATA SOURCE AzureStorage
WITH (
TYPE = HADOOP,
LOCATION = 'wasbs://<blob_container_name>@<azure_storage_account_name>.blob.core.windows.net',
CREDENTIAL = AzureStorageCredential
);
-- D: Create an external file format
-- FORMAT_TYPE: Type of file format in Azure storage (supported: DELIMITEDTEXT, RCFILE, ORC, PARQUET).
-- FORMAT_OPTIONS: Specify field terminator, string delimiter, date format etc. for delimited text files.
-- Specify DATA_COMPRESSION method if data is compressed.
CREATE EXTERNAL FILE FORMAT TextFile
WITH (
FORMAT_TYPE = DelimitedText,
FORMAT_OPTIONS (FIELD_TERMINATOR = ',')
);
-- E: Create the external table
-- Specify column names and data types. This needs to match the data in the sample file.
-- LOCATION: Specify path to file or directory that contains the data (relative to the blob container).
-- To point to all files under the blob container, use LOCATION='.'
CREATE EXTERNAL TABLE dbo.DimDate2External (
DateId INT NOT NULL,
CalendarQuarter TINYINT NOT NULL,
FiscalQuarter TINYINT NOT NULL
)
WITH (
LOCATION='/datedimension/',
DATA_SOURCE=AzureStorage,
FILE_FORMAT=TextFile
);
-- Run a query on the external table
SELECT count(*) FROM dbo.DimDate2External;Now that the external table is created, you can load the data into SQL Data Warehouse.
-- Load the data from Azure blob storage to SQL Data Warehouse
CREATE TABLE dbo.DimDate2
WITH
(
CLUSTERED COLUMNSTORE INDEX,
DISTRIBUTION = ROUND_ROBIN
)
AS
SELECT * FROM [dbo].[DimDate2External];Analyze Big Data to uncover insights
How can we handle live operational data, clean it, and apply predictive analytics to it?
We want to implement an analytics system in order to track the behavior of the web site visitors. The system should allow us to better understand customer navigation patterns, and extract information on how well products are sold in the store. For these tasks, we have logs generated by the web servers in which the application is hosted.
As our user base expands, so does the size of the logs. This is affecting our ability to transform this unstructured data into intelligent business decisions.
Proposed solution: Process and analyze unstructured data with Apache Spark on Azure Databricks
You are already using a process to store your unstructured data in Azure Storage from when you set up PolyBase to access the files from SQL DW. Now you want to perform some advanced analytics on this data. Fortunately, Azure Storage is compatible with Azure Databricks clusters. These options, as with Azure SQL Data Warehouse, allow you to separate your storage from compute so that they are independently scaled. As an added bonus, Spark is more than capable of handling the larger files in a performant way.
Apache Spark is an open-source processing framework that runs large-scale data analytics applications. Spark is built on an in-memory compute engine, which enables high-performance querying on big data. It takes advantage of a parallel data-processing framework that persists data in-memory and disk if needed. This allows Spark to deliver 100-times faster speed compared to other, similar big data SQL platforms, and a common execution model for tasks such as extract, transform, load (ETL), batch, interactive queries, and streaming workloads.
Azure Databricks is a fast, easy, and collaborative Apache Spark-based analytics platform optimized for Azure. It was created to bring Databricks' Machine Learning, AI, and Big Data technology to the trusted Azure cloud platform. It was designed in collaboration with the team started the Spark research project at UC Berkeley — which later became Apache Spark — for optimal performance on Azure cloud.
There are other advantages of using Azure Databricks over standard Apache Spark offerings:
Interactivity and collaboration
Version & source control

Advanced security
World-class notebooks
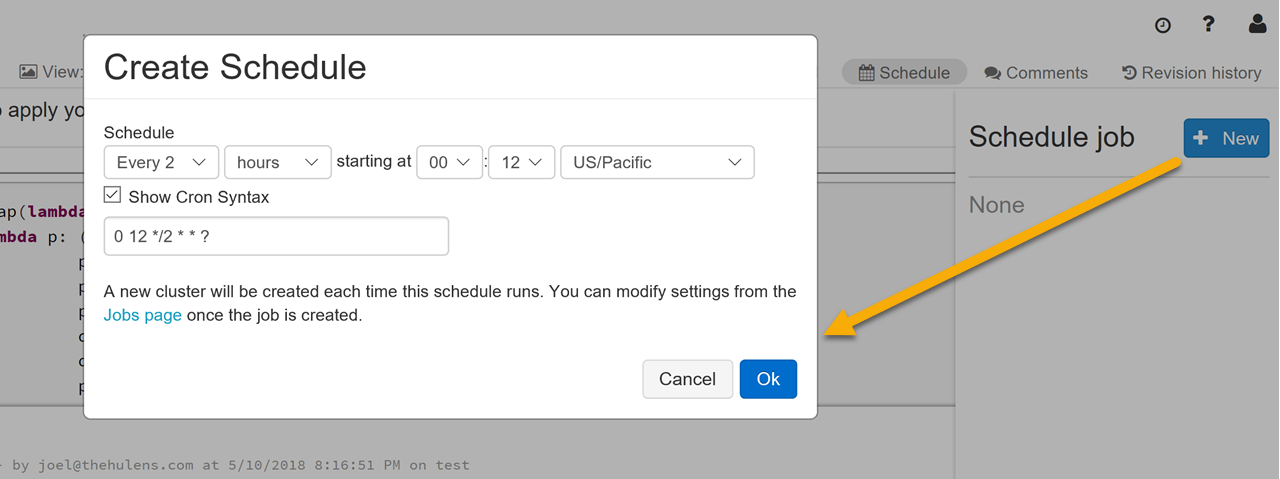
Built-in scheduling
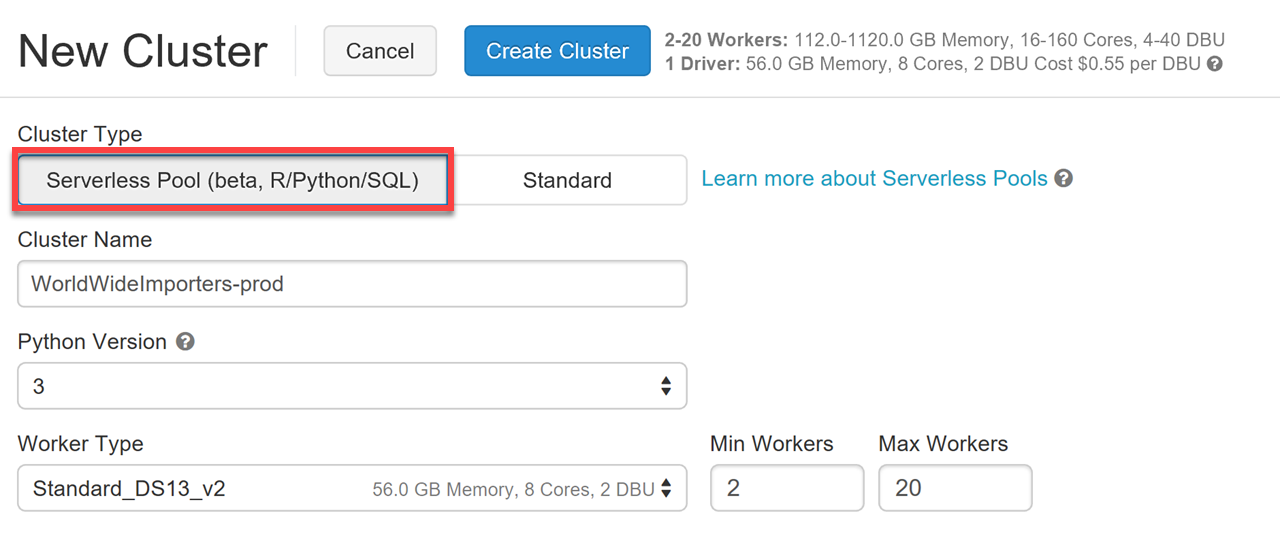
Auto-scaling & serverless
To begin, we'll explore the log data with a Python script that gets executed by the Spark engine. The Spark context is named spark in this case. The data is separated by pipes and includes a header row. The data is stored in Blob storage that is attached to the cluster. Thus, a wasbs:// path is defined to access the retail data.
import pprint, datetime
from pyspark.sql.types import *
from pyspark.sql.functions import date_format,unix_timestamp
df = spark.read.csv("wasbs://dbcontainer@databricksstore.blob.core.windows.net/retaildata/rawdata/weblognew/*/*/weblog.txt",sep="|",header=True)Now let's show the top five results from the DataFrame we created.
df.show(5)By default, all of the columns are treated as strings. We'll provide a schema as an input to the csv function so we can work with proper data types. To validate, we'll print the types from the resulting DataFrame to validate that the schema was properly applied.
weblogs_schema = StructType([
StructField('UserId',LongType(),False),
StructField('SessionId', StringType()),
StructField('ProductId', IntegerType()),
StructField('Quantity', IntegerType()),
StructField('Price', DoubleType()),
StructField('TotalPrice', DoubleType()),
StructField('ReferralURL', StringType()),
StructField('PageStopDuration', IntegerType()),
StructField('Action', StringType()),
StructField('TransactionDate', StringType())])
df = spark.read.csv("wasbs://dbcontainer@databricksstore.blob.core.windows.net/retaildata/rawdata/weblognew/*/*/weblog.txt",
schema=weblogs_schema,
sep="|",
header=True
)
pprint.pprint(df.dtypes)During exploration, it was discovered that some of the TransactionDate values are incorrectly formatted or null. Since this field is crucial to our queries and analysis, we will clean this data by filtering out those rows whose TransactionDate could not be parsed/formatted. Afterwards, we'll print the schema and observe that the new CleanedTransactionDate column is assigned the timestamp date type.
cleaned_df = df.select("*",
date_format(
unix_timestamp("TransactionDate","M/d/yyyy h:mm:ss a").cast("timestamp"),
"yyyy-MM-dd HH:mm:ss").cast("timestamp").alias("CleanedTransactionDate")
).where("CleanedTransactionDate IS NOT NULL")
cleaned_df.printSchema()Now that we're satisfied with the prepared data, let's save it to a persistent global table. This will allow us to query it with Hive as well as with Spark. The data will be stored as a series of parquet files, providing a performance boost. We'll also save the prepared data back to Blob storage so that it can be imported into SQL Data Warehouse.
We can simply use the %sql cell magic to switch the mode of the cell from running Python to running SQL. Everything on the lines below %sql is SQL that SparkSQL will execute for us.
cleaned_df.write.mode("overwrite").saveAsTable("weblogs")
cleaned_df.write.mode("overwrite").csv("wasbs://dbcontainer@databricksstore.blob.core.windows.net/output/prepared/weblogs.csv")
%sql
SELECT * FROM weblogs LIMIT 5The PolyBase script that was previously created can be modified to read the CSV files consisting of prepared data and save it to SQL Data Warehouse. It can run within a stored procedure that is periodically executed by an Azure Data Factory pipeline that accesses the files and passes the file names as parameters to the stored procedure. The Data Factory pipeline can be further modified to first execute the Spark process, then execute the stored procedure that updates the tables in SQL Data warehouse after the Spark process successfully completes.
Now with all this data, Advanced Analytics come into play
The World Wide Importers data engineers have used Azure Databricks notebooks to prepare and clean the click-stream, user, and product data so that it can be analyzed through the help of a machine learning model. The model can be built and trained within Azure Databricks, and multiple users can share and iterate on the model while taking advantage of Azure Databrick's ability to track and manage its versions.
Custom AI using trained machine learning models
In addition to fast and accurate unstructured data processing, it is possible to conduct machine learning within Spark, using the same data that is being processed. Machine learning can help develop product recommendations to customers and produce predictive insights. To do this, Spark provides a general machine learning library, MLlib, that is designed for simplicity, scalability, and easy integration with other tools. Coupled with the scalability, language compatibility, and speed of Spark, we can iterate through advanced analysis and provide machine learning capabilities quickly, and at scale.
We will use the prepared click-stream, user, and product data from the web logs and train a product recommendation model using Spark's built-in collaborative filtering algorithm - Alternating Least Squares (ALS). This model will be used to pre-compute the user to product recommendation for every user, save this in a table, then use it to retrieve 10 product recommendations for a given user.
First, we need to import the modules and functions we'll use in our Python script on the Spark cluster. Then we'll select a significant subset of our data to use in training the model.
Notice that this references the CleanedTransactionDate column we defined in the prepared version of our data.
from pyspark import SparkContext
from pyspark.sql import *
from pyspark.sql.types import *
import os
from pyspark.ml.recommendation import ALS
from pyspark.sql.functions import UserDefinedFunction
train = spark.sql("select * from weblogs where cleanedtransactiondate between '2017-03-01' and '2017-05-31'")
Now we will define the user's rating by actions that they take when using the website, instead of relying on them intentionally providing a star rating to certain products. We do this by applying weighted values to these actions, where purchasing an item is assigned the highest value, and browsing a product is assigned the lowest. This is assigned to a local variable named ActionPoints.
Next, we create a new DataFrame that contains the a tuple with only the data we are interested in (train), plus the value of the action taken. This will configure our rating to include the userId, ProductId, and the assigned Points.
ActionPoints = {"Browsed":30, "Add To Cart":70, "Purchased":100}
mapActionToPoints = UserDefinedFunction(lambda a: ActionPoints[a], IntegerType())
ratings_df = train.select(train.UserId, train.ProductId, mapActionToPoints(train.Action).alias('ActionPoints'))
ratings_df.cache()
ratings_df.take(5)
Now, we will train the model. This process takes some time, but the trained model can be saved to disk and re-used without having to wait the same amount of time it took to train the model. Here we'll save it to Azure Blob Storage, which is attached to the Spark cluster. After saving, we'll use the %sh shell magic to confirm the model was successfully saved.
als = ALS(maxIter=10, regParam=0.01, userCol="UserId", itemCol="ProductId", ratingCol="ActionPoints")
model = als.fit(ratings_df)
model.write().overwrite().save("/models/cfmodel")
%sh
hdfs dfs -ls /models/cfmodel
We will now test the model with a new DataFrame containing the set of UserIDs and ProductIDs for which we want to predict a rating. This also references a view of the product data extracted from the log files. Then we'll use the transform method on the model to create another DataFrame that includes all the columns from the test DataFrame and adds a new prediction column that indicates the confidence of the prediction. At the bottom of the script, we're creating a new DataFrame of a cleaned up version of the prediction DataFrame by omitting rows without a prediction (NaN), then caching and displaying a sample of the data.
test_users_df = spark.sql("select distinct w.UserId, p.ProductId from weblogs w cross join Products_View p where w.UserId > 3686 and w.UserId < 3706")
predictions = model.transform(test_users_df)
user_product_ratings = predictions.select("UserId", "ProductId", "prediction").where("not isnan(prediction)").orderBy("UserId", predictions.prediction.desc())
user_product_ratings.cache()
user_product_ratings.createOrReplaceTempView("UserProductRatings_View")
user_product_ratings.show(5)We'll create a simple function we can use to pass in a User Id and retrieve the top ten recommended products for that user. This references a users view that was extracted from the log files.
def GetRecommendedProductsForUser(UserId):
user_product_mapping = spark.sql("SELECT * FROM UserProductRatings_View WHERE UserId =" + str(UserId))
recommended_products = user_product_mapping.join(
products_DF_with_price, user_product_mapping.ProductId == products_DF_with_price.ProductId
).orderBy( user_product_mapping.prediction.desc() )
print("User Information:")
users_data = spark.sql("SELECT FirstName, LastName, Gender, Age from users WHERE id =" + str(UserId))
users_data.show(1)
print("Recommended Products:")
recommended_products.show(10)
The function is invoked by passing in a User Id. The higher the rating displayed in the prediction column, the more confident we are of the recommendation:
GetRecommendedProductsForUser(UserId = 3696)Now select a UserId value to pass into the `GetRecommendedProductsForUser` function to see the result:
 Artificial intelligence helps maximize customer understanding
Artificial intelligence helps maximize customer understanding
The trained model can be used in conjunction with the batch processing we created earlier in order to store the top ten recommended products for each user for future reference. Later, we'll look at how to operationalize the model, meaning, make it available to create predictions on-demand through a web interface that can be accessed from any web browser or mobile application.
Deep learning
In addition to creating machine learning models, as described above, Azure Databricks also supports using deep learning frameworks like Tensorflow and CNTK to build and apply neural networks. While in most cases, you will train neural networks on a single machine, Azure Databricks supports training a deep neural network in parallel across multiple machines, also known as distributed deep learning.
Some deep learning libraries and frameworks that can be used within Azure Databricks are:
Deep learning libraries are best used within Spark jobs for tasks such as:
- Distributed inference: Each worker task makes predictions for a subset of instances.
- Distributed model selection: Each worker task fits a model using a different set of training parameters. Each worker task uses a local dataset.
We would like to store processed data in NoSQL storage for access by our web and mobile apps
Now that we have a way to process the unstructured data and make product recommendations for our users, we need a faster method of accessing that data and making it available to our audience on both web and mobile apps. The NoSQL storage should be store the data as close to our users as possible, geographically, and be able to dynamically scale to meet demand. We're also interested in managing the amount of data stored, because the product recommendations and promotions we'll be storing here will be short-lived.
Proposed solution: Store processed data in Azure Cosmos DB
Built from the ground up with global distribution and horizontal scale at its core, Azure Cosmos DB is a NoSQL database service, offering turnkey global distribution across any number of Azure regions by transparently scaling and replicating data wherever users are. Plus, it offers the ability to elastically scale throughput and storage worldwide. This will work as a fast and flexible location for hosting the processed data. Additionally, it is easily accessible from web and mobile applications, as well as various dashboards, using any number of multi-model APIs.
Azure Cosmos DB supports specifying a "time to live" (TTL) on documents within collections, which is beneficial to managing the size of the data store when the stored data is only useful for a finite period of time. With TTL, Azure Cosmos DB provides the ability to have documents automatically purged from the database after a period of time. The default time to live can be set at the collection level, and overridden on a per-document basis. Once TTL is set, either as a collection default or at a document level, Azure Cosmos DB will automatically remove documents that exist after that period of time, in seconds, since they were last modified. For this use case, we will configure the DefaultTTL value for the collection to 1,440 seconds, or one day.
The Spark to Azure Cosmos DB connector will allow us to seamlessly enable the Azure Cosmos DB instance to act as an output sink, or destination, for our Spark jobs.
To connect the Azure Databricks notebooks to Azure Cosmos DB using the pyDocumentDB library, we first need perform a few steps:
- Download the uber JAR / library
- Upload the downloaded JAR file to Azure Databricks
- Attach the uploaded libraries to your Azure Databricks cluster
# Import Necessary Libraries
import pydocumentdb
from pydocumentdb import document_client
from pydocumentdb import documents
import datetime
# Configuring the connection policy (allowing for endpoint discovery)
connectionPolicy = documents.ConnectionPolicy()
connectionPolicy.EnableEndpointDiscovery
connectionPolicy.PreferredLocations = ["Central US", "East US 2", "Southeast Asia", "Western Europe","Canada Central"]
# Set keys to connect to Azure Cosmos DB
masterKey = 'le1n99i1w5l7uvokJs3RT5ZAH8dc3ql7lx2CG0h0kK4lVWPkQnwpRLyAN0nwS1z4Cyd1lJgvGUfMWR3v8vkXKA=='
host = 'https://wideworldimporters.documents.azure.com:443/'
client = document_client.DocumentClient(host, {'masterKey': masterKey}, connectionPolicy)
Now, the existing scripts can be updated to save directly to the Azure Cosmos DB collection by specifying a write configuration, then passing that as an option to the DataFrame we want to save, as well as setting the format to com.microsoft.azure.cosmosdb.spark:
# Write configuration
writeConfig = {
"Endpoint" : "https://wideworldimporters.documents.azure.com:443/",
"Masterkey" : "le1n99i1w5l7uvokJs3RT5ZAH8dc3ql7lx2CG0h0kK4lVWPkQnwpRLyAN0nwS1z4Cyd1lJgvGUfMWR3v8vkXKA==",
"Database" : "UserPromotions",
"Collection" : "product_recommendations",
"Upsert" : "true"
}
users_data.write.format("com.microsoft.azure.cosmosdb.spark").options(**writeConfig).save()With that, the product recommendations provided by the trained machine learning model will be saved to Azure Cosmos DB.
How can we access our trained models from outside of Spark?
We would like to be able to individually send data to our trained machine learning models from our client apps on-demand, outside of the existing pipeline that processes data from logs. For example, the web app can track how long a user has been browsing the website and proactively make suggestions based on certain actions. If the user has added an item to the shopping cart but they've been idle for a certain amount of time, we want to be able to provide a one-time discount on the item, based on the likelihood of them abandoning the item and not purchasing it. The discount should have a short expiration time, like 5 minutes, that we can adjust for effectiveness as time goes on.
Proposed solution: Use Azure Machine Learning to host and operationalize the trained models
Azure Machine Learning is an integrated, end-to-end data science and advanced analytics solution that would be ideal for managing and deploying trained machine learning models. Azure Databricks notebooks can be used to perform data exploration and understanding. Then, following the steps above to build a machine learning model , the next step is to train the model using an Azure Databricks notebook, then export that trained model to a file . This file can be used to import the model into Azure Machine Learning Model Management.
Azure Machine Learning Model Management allows you to deploy your trained Spark model as containerized Docker-based web services. You can deploy the web services locally for testing, then to Azure for production-ready consumption. Read [Deploying a Machine Learning Model as a web service] for more information.
The deployment steps are as follows:
- Use your saved, trained, Machine Learning model
- Create a schema for your web service's input and output data
- Create an Docker-based container image
- Create and deploy the web service
Once you deploy a model as a real-time web service, you can send it data and get predictions from a variety of platforms and applications. The real-time web service exposes a REST API for getting predictions. You can send data to the web service in a single or multi-row format to get one or more predictions at at time.
Enabling real-time processing
Many of today's big data solutions must act on data in motion at any given point in time. In other words, real-time streaming data. In most cases, this data is most valuable at its time of arrival. Some examples include ingesting sensor data from IoT devices to analyze the values and detect equipment failures in real-time, or evaluating browsing and purchasing trends in real-time in an e-commerce site.
A typical streaming architecture consists of one or more data sources generating events (sometimes in the millions per second) that need to be ingested very quickly to avoid dropping any useful information. This is handled by the Stream Buffering, or event queuing, layer by a service such as Kafka or Event Hubs. Once you collect your events, you can then analyze the data using any real-time analytics system within the Stream Processing layer, such as Storm, Spark Structured Streaming, or similar.
Can we introduce real-time streaming data from our users' clickstream behavior into our analytics pipeline?
We would like to provide a more responsive customer experience through real-time e-commerce promotions and offers. Ideally, we would be able to instantly analyze clickstream behavior and immediately respond with corresponding offers for thousands of users.
Proposed solution: Set up a Big Data Lambda architecture
The lambda architecture is a pipeline architecture originally devised with the goal to reduce complexity of a real-time analytics pipeline by constraining incremental computation activities to only a small portion of this architecture. This is accomplished by creating two paths for data flow into the pipeline:
- A "hot" path, or speed layer, used for rapid ingestion of latency-sensitive (or real-time) data, meant for rapid consumption by analytics clients
- A "cold" path, or batch layer, that stores all of the incoming data for batch processing, where data processing can take anywhere from minutes to hours
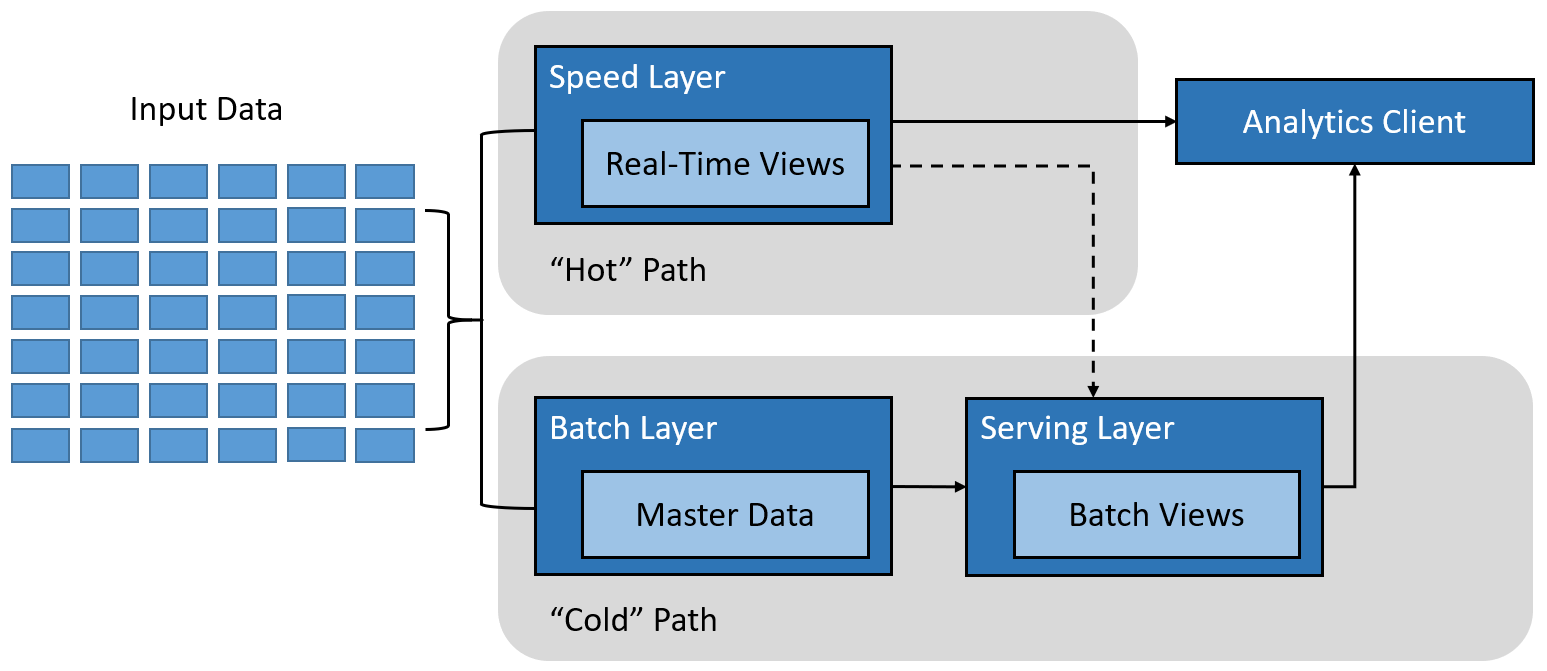
Clickstream data is an information trail a user leaves behind while visiting a website, such as that which is captured in the website log files. If you recall from the Spark segment above, the log files contain data elements such as a date and time stamp, the visitor's IP address, the URLs of the pages visited, and a user ID that uniquely identifies the user.
Real-time stream processing with Apache Kafka and Azure Databricks
We currently have a method in place for processing this data in batch, which we created earlier. This will become the "cold" path, or batch layer of our lambda architecture. We will process this data in real-time using a combination of an HDInsight Kafka cluster and Spark Structured Streaming for the "hot" path.
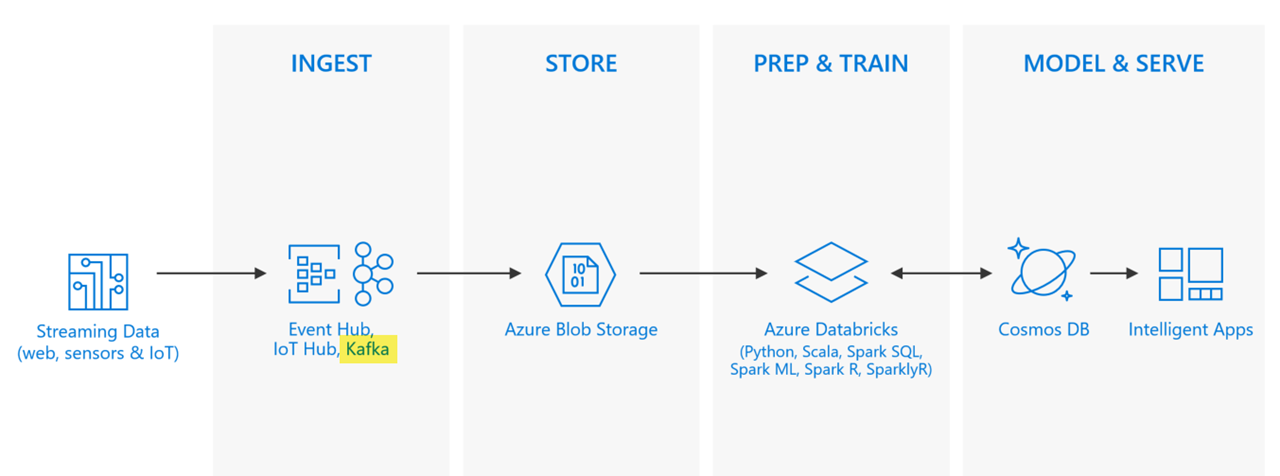
Spark has a great advantage over many other popular big data engines, in that it can be used for both batch and stream processing, allowing us to reuse much of the same code for both processing needs. In this case, the batch processing will remain the same, where the processed data is saved to Blob storage for ingest into SQL Data Warehouse. The processed streaming data will be saved to Cosmos DB to allow a large amount of users to quickly access the data in a highly scalable way.
Apache Kafka is an open-source distributed streaming platform that can be used to build real-time streaming data pipelines and applications. Kafka also provides message broker functionality similar to a message queue, where you can publish and subscribe to named data streams. Kafka on HDInsight provides you with a managed, highly scalable, and highly available service in the Microsoft Azure cloud.
Please note that Apache Kafka on HDInsight does not provide access to the Kafka brokers over the public internet. Anything that talks to Kafka must be in the same Azure virtual network as the nodes in the Kafka cluster, or within another Azure virtual network that is peered with the Kafka virtual network. To allow your Azure Databricks cluster to subscribe to Kafka topics, you must peer the Kafka cluster to the Azure Databricks cluster .
The log entries are fed into a Kafka topic named weblogs by the logger used in the web application. A topic is a category or feed name to which records are published. This will be where your clickstream data resides within the Kafka cluster.
The clickstream data stored in the Kafka topic is read into a Spark streaming DataFrame by subscribing to the weblogs topic. The kafka DataFrame below represents an unbounded table containing the streaming data, and is your query for the streaming data.
val kafka = { spark.readStream.format("kafka")
.option("kafka.bootstrap.servers", kafkaBrokers)
.option("subscribe", kafkaTopic)
.option("startingOffsets", "earliest")
.load() }From this point, the streaming computation can be started in the background, and we can access the same trained MLlib machine learning model created earlier to create product recommendations in real time. The results of the product recommendations can be saved to Azure Cosmos DB to show the user their personalized recommendations in short order.
Another way this clickstream data can be used in this scenario is to determine how long an item has been sitting in the user's shopping cart and, if it appears as though they are likely to abandon the shopping cart without making a purchase, with the help of another trained model, then a one-time discount can be offered to the user for that item, which expires in 5 minutes. Putting this architecture in place opens up many doors for boosting customer retention and sales, which would otherwise be difficult or impossible using traditional methods.
Artificial Intelligence
For most people, the term "Artificial Intelligence" conjures images of science fiction and dubious robots. Pop culture has taken the term and run with it in many examples of wild, imaginative futuristic scenarios. But Artificial Intelligence (or AI) is more prevalent in our world today than many realize. The most obvious examples that come to mind are the helpful virtual assistants on our smart phones and home automation devices, which can understand spoken language, and perform actions and reply in a conversational manner in return. There are more mundane examples as well, that help businesses analyze data and predict trends to give them a competitive edge.
AI is traditionally a difficult field of study to enter into, and its foundation upon specialized math and science disciplines has created a barrier of entry that only a small percentage of business have been able to overcome in the past. However, we have entered a new era of democratized AI, or, AI as a service, if you will. For example, Azure Cognitive Services helps you infuse your apps with AI through intelligent algorithms that allow them to see, hear, speak, understand, and interpret your user needs through natural methods of communication. You are not required to have any knowledge of advanced algorithms, nor do you need to install and configure anything to get started. Simply create a new service with a few clicks, and get started right away with simple calls from your application.
We would like to infuse AI into apps to actively engage with customers
We want to understand how to intelligently engage with our customers through natural methods of communication, whether spoken or written. Our challenge is, we don't employ data scientists and engineers who are trained to build AI solutions. We've heard that, in order to intelligently interpret how our customers feel, and automate appropriate responses to their needs, we have to create sophisticated algorithms. Where do we even start?
Proposed solution: Use Cognitive Services for sentiment analysis, and Bot Framework to automate personalized interactions
Azure Cognitive Services APIs can be combined with the Bot Framework to engage your users on a whole new level, in a completely automated way, without needing to spend months creating and refining sophisticated algorithms. You can use the Text Analytics API to evaluate your customer's sentiment (are they happy, or upset), and couple that with the Language Understanding Intelligent Service (LUIS) to understand any commands that they send, like "put me in contact with a real person", or "can you find me any sales on peacock decor?". Then you can use the Azure Bot Service to intelligently respond to your users, or perform actions as appropriate, using this information. All of this can be built using your favorite programming language, such as C# or Node.js.`
In the example below, we have an ASP.NET MVC controller action that receives a request from a user in a chat session. The Bot Framework SDK binds the incoming data to an Activity, most of which are of type Message, which will contain the text and any attachments that the user sent to the bot. This is how we can see if the activity is a message, and if so, we'll pass the information to a LUIS dialog to determine the user's intent:
switch (activity.GetActivityType())
{
case ActivityTypes.Message:
await Conversation.SendAsync(activity, () => new WIILuisDialog());
break;
...
}
The LUIS dialog helps control the conversation with the user. Within the dialog, you define different intents, which are actions that LUIS has mapped to what the user typed in their message. If no matching intent was found, then the NoneIntent intent handler is called. Otherwise, a matching intent handler is called to take some action on the request:
[Serializable]
public class WWILuisDialog : LuisDialog<object>
{
public WWILuisDialog() : base(new LuisService(new LuisModelAttribute(ConfigurationManager.AppSettings["LuisAppId"],
ConfigurationManager.AppSettings["LuisAPIKey"])), ICustomerServiceHelper customerServiceHelper)
{
}
[LuisIntent("None")]
public async Task NoneIntent(IDialogContext context, LuisResult result)
{
await context.PostAsync($"I'm sorry :( I don't understand what you mean. Would you like to get in touch with someone who can help?");
context.Wait(MessageReceived);
}
// Go to https://luis.ai and create a new intent, then train/publish your luis app.
// Connects the user to customer service.
[LuisIntent("SpeakToCustomerService")]
public async Task SpeakToCustomerService(IDialogContext context, LuisResult result)
{
await context.PostAsync($"Thank you for your time. I am now getting you in touch with someone in customer service."); //
await customerServiceHelper.Contact(context, result.Query);
context.Wait(MessageReceived);
}
// Finds sales on types of items.
[LuisIntent("FindSales")]
public async Task FindSales(IDialogContext context, LuisResult result)
{
var salesLinks = await saleItemsHelper.Find(context, result.Intents, result.Entities);
if (!string.IsNullOrWhitespace(salesLinks))
{
await context.PostAsync($"You're in luck! This is what I found: {salesLinks}");
}
else
{
await context.PostAsync($"Well, I looked and looked, but couldn't find any sales. I even asked our best salespeople...");
}
context.Wait(MessageReceived);
}
}To determine the user's sentiment, we'll use the Sentiment Analysis API, which is part of the Text Analytics service. The service takes a simple JSON-formatted document containing one or more phrases you wish to evaluate. For example, if we send two recent messages that the customer typed to the Bot via the chat application, we can see what the sentiment is for each:
{
"documents": [
{
"language": "en",
"id": "1",
"text": "overall, I love your products and have had great customer service from your sales reps"
},
{
"language": "en",
"id": "2",
"text": "But, the last time I went in, I felt like I was being ignored and even looked down on!"
}
]
}Notice that the JSON includes id, language, and text fields. The id is simply used for correlating responses from the service to the phrases being sent. You can have up to 1,000 of these per collection.
At this point, simply send the JSON payload to the service endpoint, along with the Text Analytics access key in the header. The endpoint will be something like this: https://westus.api.cognitive.microsoft.com/text/analytics/v2.0/sentiment. Notice the /sentiment at the end of the address, which tells the service to use the Sentiment Analysis API.
Here's a sample response from the service:
{
"documents": [
{
"score": 0.9999237060546875,
"id": "1"
},
{
"score": 0.0000540316104888916,
"id": "2"
}
],
"errors": []
}As you can see, given a scale of 0.0 (negative) to 1.0 (positive), the first phrase the customer typed was deemed to be very positive, while the second phrase was quite negative. A score of around 0.5 is considered neutral. You can craft your app to take this information into account when deciding how to automatically reply to the customer, or take other actions as appropriate.
Proposed solution: Use Cognitive Services Custom Vision Service with Bot Framework to find product by user-supplied photo
Another capability that can be added to the bot is image recognition. This can open up the ability for a shopper to take a photo of a product they're interested in, such as a friend's pair of shoes, and receive a link to the product, or even have it added to the shopping cart. To help achieve this, you could use Azure Cognitive Services' Custom Vision Service. You start out by building a classifier and training it with at least 30 images per tag, or product. While this minimum image requirement is relatively small for training image classification, this does put special constraints on the solution. Given the number of product images you would need on hand, you would need to be subjective about the class of products you wish to offer using this special service. Another thing to consider is that currently, this service is an image classifier, not an object recognizer. What this means is that the object you are trying to recognize should be the most prominent thing in the picture. To this end, simply instruct your customers to take a close-up shot of the item or crop the image accordingly.
In our solution, we'll create a new Custom Vision Services classifier for shoes and assign it the Retail domain. We will create tags for each shoe model we want the classifier to recognize. This can all be done through the Custom Vision Service website, but would take a very long time for a large number of tags. A better alternative in this case would be to use the Custom Vision SDK to programmatically create the classifier and upload all of the required images for training.
Here is a simple console application that creates a new Custom Vision API project named "Men's Shoes" and creates tags for two specific models: Nike Air Zoom Pegasus 34, and Nike Free RN Motion Flyknit 2017. It then uploads ~13 images of each in different colors, then kicks off a new training iteration for the project. It demonstrates two methods for uploading the images. The first method is one-at-a-time, and the second method is uploading as a batch.
class Program
{
private static List<MemoryStream> nikeAirZoomPegasus34Images;
private static List<MemoryStream> nikeFreeRNMotionFlyknit2017Images;
private static MemoryStream testImage;
static void Main(string[] args)
{
// You can either add your training key here, pass it on the command line, or type it in when the program runs
string trainingKey = GetTrainingKey("193147d51d63298883c3947f97c5caf6", args);
// Create the Api, passing in a credentials object that contains the training key
var trainingCredentials = new TrainingApiCredentials(trainingKey);
var trainingApi = new TrainingApi(trainingCredentials);
// Create a new project
Console.WriteLine("Creating new project:");
var project = trainingApi.CreateProject("Men's Shoes");
// Make two tags in the new project
var pegasus34Tag = trainingApi.CreateTag(project.Id, "Nike Air Zoom Pegasus 34");
var flyknit2017Tag = trainingApi.CreateTag(project.Id, "Nike Free RN Motion Flyknit 2017");
// Add some images to the tags
Console.WriteLine("\tUploading images");
LoadImagesFromDisk();
// Images can be uploaded one at a time
foreach (var image in nikeAirZoomPegasus34Images)
{
trainingApi.CreateImagesFromData(project.Id, image, new List<string>() { pegasus34Tag.Id.ToString() });
}
// Or uploaded in a single batch
trainingApi.CreateImagesFromData(project.Id, nikeFreeRNMotionFlyknit2017Images, new List<Guid>() { flyknit2017Tag.Id });
// Now there are images with tags start training the project
Console.WriteLine("\tTraining");
var iteration = trainingApi.TrainProject(project.Id);
// The returned iteration will be in progress, and can be queried periodically to see when it has completed
while (iteration.Status == "Training")
{
Thread.Sleep(1000);
// Re-query the iteration to get it's updated status
iteration = trainingApi.GetIteration(project.Id, iteration.Id);
}
// The iteration is now trained. Make it the default project endpoint
iteration.IsDefault = true;
trainingApi.UpdateIteration(project.Id, iteration.Id, iteration);
Console.WriteLine("Done!\n");
// Now there is a trained endpoint, it can be used to make a prediction
// Get the prediction key, which is used in place of the training key when making predictions
var account = trainingApi.GetAccountInfo();
var predictionKey = account.Keys.PredictionKeys.PrimaryKey;
// Create a prediction endpoint, passing in a prediction credentials object that contains the obtained prediction key
var predictionEndpointCredentials = new PredictionEndpointCredentials(predictionKey);
var endpoint = new PredictionEndpoint(predictionEndpointCredentials);
// Make a prediction against the new project
Console.WriteLine("Making a prediction:");
var result = endpoint.PredictImage(project.Id, testImage);
// Loop over each prediction and write out the results
foreach (var c in result.Predictions)
{
Console.WriteLine($"\t{c.Tag}: {c.Probability:P1}");
}
Console.ReadKey();
}
private static string GetTrainingKey(string trainingKey, string[] args)
{
if (string.IsNullOrWhiteSpace(trainingKey) || trainingKey.Equals("<your key here>"))
{
if (args.Length >= 1)
{
trainingKey = args[0];
}
while (string.IsNullOrWhiteSpace(trainingKey) || trainingKey.Length != 32)
{
Console.Write("Enter your training key: ");
trainingKey = Console.ReadLine();
}
Console.WriteLine();
}
return trainingKey;
}
private static void LoadImagesFromDisk()
{
// this loads the images to be uploaded from disk into memory
nikeAirZoomPegasus34Images = Directory.GetFiles(@"..\..\..\Images\Nike Air Zoom Pegasus 34").Select(f => new MemoryStream(File.ReadAllBytes(f))).ToList();
nikeFreeRNMotionFlyknit2017Images = Directory.GetFiles(@"..\..\..\Images\Nike Free RN Motion Flyknit 2017").Select(f => new MemoryStream(File.ReadAllBytes(f))).ToList();
testImage = new MemoryStream(File.ReadAllBytes(@"..\..\..\Images\Test\air-zoom-pegasus-34-mens-running-shoe.jpg"));
}
}
Result:
Creating new project:
Uploading images
Training
Done!
Making a prediction:
Nike Air Zoom Pegasus 34: 100.0%
Nike Free RN Motion Flyknit 2017: 0.0%You can view the Custom Vision project created on the Custom Vision Service website, along with the trained images uploaded within the new tags. From here, it's also possible to add more images, view the performance of each training iteration, view prediction results, re-train, and submit a quick test.
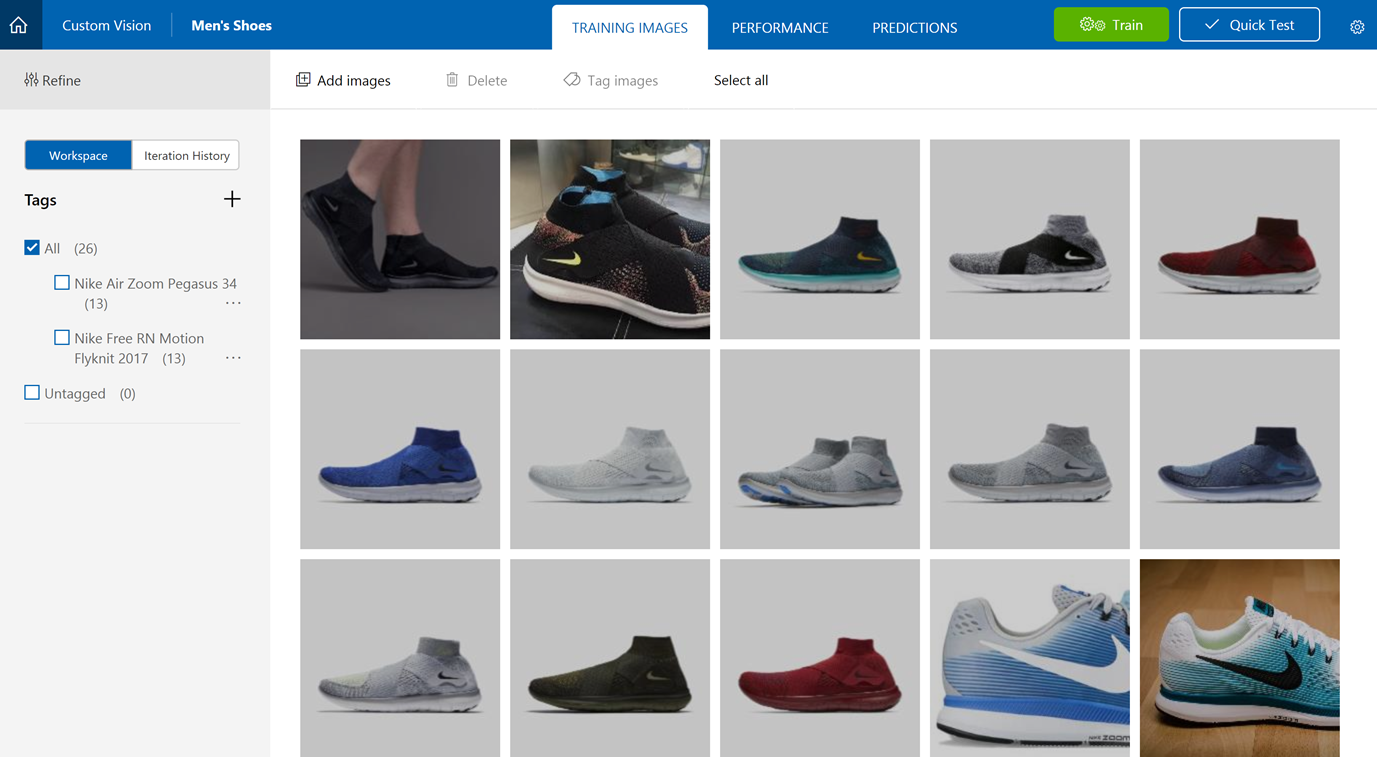
Now let's test a couple of predictions and see what the result looks like:
$(function() {
$.ajax({
url: "https://southcentralus.api.cognitive.microsoft.com/customvision/v1.0/Prediction/fb9e68c4-e202-4a06-948b-ea4345e5125d/url",
beforeSend: function(xhrObj){
// Request headers
xhrObj.setRequestHeader("Content-Type","application/json");
xhrObj.setRequestHeader("Prediction-key","3e8d08f742c749258221f5371e0620b9");
},
type: "POST",
// Request body
data: '{"Url": "http://www.wideworldimporters.com/media/uploads/17f82f742ffe127f42dca9de82fb58b1/nike-air-zoom-pegasus-34.jpg"}'
})
.done(function(data) {
console.info(data);
})
.fail(function() {
alert("error");
});
});Select an image to submit to the Custom Vision project API to see what it predicts.
Nike Air Zoom
Pegasus 34

Nike Free RN Motion
Flyknit 2017

There is a 99.8% match to Nike Air Zoom Pegasus 34 and a 0% match (converted from scientific notation) to Nike Free RN Motion Flyknit 2017.
Notice how the return values are sorted from most likely match on top down to the lowest probability.
There is a 99.9% match to Nike Free RN Motion Flyknit 2017 and a 0% match (converted from scientific notation) to Nike Air Zoom Pegasus 34.
Notice how the return values are sorted from most likely match on top down to the lowest probability.
More complex computer vision scenarios
In the scenario above, the Cognitive Services Custom Vision Service is used to successfully find products based on an image that contains a single product. This is a great option for rapidly building a solution without needing to create and train complex models, but what if you need the ability to recognize multiple products within an image? In this case, you will need to build a model using a deep learning library like TensorFlow for object identification. But training a deep neural network on thousands of images takes a lot of time. As such, this process will benefit from using multiple GPUs in parallel. Since Azure Databricks does not offer GPUs for such training, a great option here would be to use Azure Batch AI.
With Azure Batch AI, you can train your AI models with GPUs in parallel, saving time. It supports any framework or library and the infrastructure is managed for you. You just submit a job and the service will scale out Azure VMs for you, which include the latest NVIDIA GPUs.
Next Steps
- Transactional apps interactive cloud app scenario
- Real-time personalization interactive cloud app scenario
- Developer Immersion "Developing with Data" labs on GitHub
- Create your Azure free account today
Resources
- Azure SQL Data Warehouse
- Elastic pools
- Elastic jobs
- Power BI
- Azure Analysis Services
- PolyBase
- Azure Databricks
- Azure Cosmos DB
- Azure Machine Learning
- HDInsight Apache Kafka
- Spark Streaming
- Azure Bot Service
- Azure Cognitive Services
- Azure Batch AI